
Linux 常用命令 | head 详解
Linux 命令行工具提供了足够丰富的命令用于管理服务器上的文件和目录。其中最常用的命令之一是 head,它允许我们只查看文件的前几行内容,这在查看超大文件(文件大小为几个 GB 以上)时尤其有用。在这篇博文中,我们将详细讨论该命令的使用说明、注意事项、技巧窍门等,以充分利用该命令。 使用说明head 命令用于显示一个文件的前几行。要使用该命令,只需输入 head 和你想查看的文件名即可。例如,要查看一个名为 example.log 的文件的前10行,你可以输入以下命令: 1head -n 10 example.log 其中,-n 选项用于指定要查看的行数。如果不指定数字,它将默认为 10 行。还可以使用 - 号来表示除了文件最后多少行外输出所有行内容。例如,要查看文件的所有行,但不包括最后的 11 行,可以输入以下命令: 1head -n -11 example.log 注意事项在使用 head 命令时,有两个地方需要注意: 首先,注意不要使用 > 操作符意外覆盖原来的文件。例如,执行以下命令会导致 example.log 文件被其前 10 行的内容覆盖,相当于...
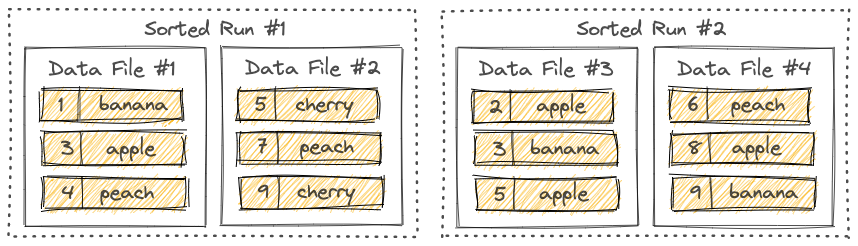
Flink Table Store文件存储结构——LSM树
本文简要介绍了 Flink Table Store 底层文件存储的数据结构——LSM 树的相关概念。 LSM 树,亦称日志结构合并树,英文为 log-structured merge-tree。 Sorted Runs如下图所示,LSM 树将文件组织成若干个 Sorted Run,一个 Sorted Run 由一个或多个数据文件组成,每个数据文件只会隶属一个 Sorted Run。数据文件中的记录按主键排序,在一个 Sorted Run 中,数据文件的主键范围不会有重叠的情况。但在不同的 Sorted Run 中主键范围有可能会重叠,甚至是包含相同的主键。 当查询 LSM 树时,必须先合并所有的 Sorted Run,根据用户指定的合并引擎和每条记录的时间戳合并具有相同主键的所有记录。而新的记录在写到 LSM 树之前会先缓存在内存中,当内存缓冲区满时,内存中的所有记录会先进行排序,然后再刷到磁盘上,此时就创建了一个新的 Sorted Run。 Compaction随着越来越多的记录写入 LSM 树,Sorted Run 的数量也会越来越多。因为查询 LSM...
Filebeat工作原理
本文主要介绍 Filebeat 的两个关键组件以及它们如何共同协作完成数据采集和转发工作。理解并熟练掌握这些组件的工作原理将对后面深入学习 Filebeat 的各种功能和特性,尤其是为特定使用场景配置 Filebeat 时大有裨益。 Filebeat 由两个关键组件构成:输入(Input)和采集器(Harvester,[ˈhɑːrvɪstər])。这些组件共同协作,跟踪日志文件,并将事件数据发送到指定的输出上。 采集器采集器逐行读取文件内容并将其转换为事件,然后发送到指定的输出上。一个采集器只会跟踪一个日志文件。需要注意的是,采集器还负责文件的打开与关闭——采集文件之前需要先打开文件,采集结束之后需要关闭文件。在采集的过程中,文件会一直保持打开的状态。也就是说,如果在采集期间移除或重命名文件,采集器仍会继续读取该文件,这会导致磁盘空间不被释放,除非关闭采集器。 默认情况下,Filebeat 保持文件为打开状态的时长取决于配置项 close_inactive 设置的时长。如果一个文件在设定的时间内没有新增数据,即 Filebeat 在设定的时间内没有从该文件中采集到数据,那么...
安装Filebeat
Filebeat 在 Linux、Unix、Mac 和 Windows 上均可正常运行。根据我们当前使用的服务器的系统类型,选择适用于该系统的命令来下载和安装 Filebeat。 在 Linux 上安装 Filebeat首先,你可以试着输入 filebeat version,看看系统有没有安装 Filebeat: 12$ filebeat versionfilebeat: command not found 或者使用 whereis 命令查看, 12$ whereis filebeatfilebeat: 类似上面的命令的输出结果,说明当前系统并没有安装 Filebeat。 你可以使用以下命令下载 Filebeat 压缩包文件: 1curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.6.2-linux-x86_64.tar.gz 解压文件: 1tar xzf...
了解Filebeat:采集、转发和汇总日志的轻量型解决方案
Filebeat 是什么?Filebeat 是基于 libbeat 框架开发的一款开源的轻量型日志采集器,专为快速收集和传输多种来源的日志数据而设计。它可以从安全设备、云、容器、主机或 OT 等多种数据源采集日志,并提供一种轻量型的方法,用于转发和汇总日志与文件。 Filebeat 有什么特点?1、Filebeat 支持从多种数据源收集数据,例如安全设备、云服务、容器、主机或 OT等。 2、Filebeat 具有性能稳定、支持容错机制的特点。如果在未来某个时刻 Filebeat 因为某种原因中断,恢复正常后,它可以从中断前停止的位置继续读取并转发日志行。 3、Filebeat 支持背压机制。这意味着,如果 Filebeat 发送日志数据的速率超过接收端(例如 Logstash、Elasticsearch等)处理数据的速率,接收端会向 Filebeat 发出信号,要求 Filebeat 减慢发送速度,以避免 Filebeat 收集的数据因内存不足而被丢弃。一旦接收端处理数据的速率跟上,Filebeat 就会恢复到原来的步伐并继续传输数据。 4、Filebeat...
Flink依赖配置:Table API & SQL
我是 Flink 初学者,现在我要在 Flink 应用程序中添加支持使用 Flink SQL 进行数据统计的功能,但我不知道应该添加哪些依赖。 程序使用 Java 语言开发,Flink 版本是当前最新的 1.16.1 版本,程序的功能是使用 Flink SQL 从 Kafka 读取数据,并把读取到数据直接进行标准输出。Kafka 的数据为 Canal 程序采集 MySQL 的 Binlog 日志,所以这里我使用到的 Table API 连接器有 Kafka Connector,Canal Connector。 pom.xml...
Superset配置——连接Presto出现ERROR: Could not load database driver: PrestoEngineSpec
问题描述安装好 superset,版本 2.0.1,通过命令 superset run -p 8088 --with-threads --reload --debugger 启动 debug 模式,在界面配置 presto 数据库连接,点击 TEST CONNECTION,右下角弹出以下错误信息: 1ERROR: Could not load database driver: PrestoEngineSpec 在启动 superset 之前,服务器上已按照官方文档安装了驱动: 1pip3 install pyhive 解决方法从错误信息可以看出这是驱动问题导致的。虽然安装了正确的驱动,但是如果驱动的版本太低,同样也会有问题。通过 pip 安装默认都是最新版本,截至当前,pyhive 的最新版本为 0.6.5。 首先检查服务器上安装的 pyhive 的版本是否为最新的版本: 1pip3 list 或: 12$ pip3 list |grep PyHivePyHive 0.6.5 可以看到 PyHive 为最新版本...
查看filebeat版本
对于 Linux 服务器上已安装好的 filebeat,该如何查看 filebeat 版本? 执行命令 filebeat version 即可输出 filebeat 的版本信息。在下面的示例中,filebeat 的版本号为 7.13.4。 12$ filebeat versionfilebeat version 7.13.4 (amd64), libbeat 7.13.4 [1907c246c8b0d23ae4027699c44bf3fbef57f4a4 built 2021-07-14 18:42:41 +0000 UTC] (END)
通过Flink WebUI仪表盘上传的jar包默认存储在哪个目录下?
在 Flink WebUI 上是可以查看上传 jar 包的存放目录的。打开 Flink WebUI,点击 Job Manager,再点击 Configuration 标签页,配置项 web.tmpdir 对应的值即为上传后的 jar 包的存放目录,具体如下图所示: 登录服务器,使用 ll 命令查看目录内容: 123$ ll /tmp/flink-web-cc812fd4-effb-48f0-8ef2-d67f0700f1b4/flink-web-upload/total 159364-rw------- 1 hadoop hadoop 163186973 Jan 1 10:03 2a08ffd6-34bf-4abb-9735-2c46587fef23_flink-connectors-1.0-SNAPSHOT.jar 需要注意的是,存放在默认路径下的 jar 包,会在 Job Manager 重启后被删除。如果重启 Job Manager 后还想保留之前上传的 jar 包,可以在 Flink 的配置文件 flink-conf.yaml 添加 web.upload.dir...

Java使用Gson判断字符串是否为JSON格式
配置Maven依赖首先,在 pom.xml 文件中配置 gson 依赖项: 12345<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10</version></dependency> gson 版本根据实际情况进行选择,建议使用最新版本(见 Maven Central )。 本文使用的是 2.10 版本(当前最新版本)。 非严格验证Gson 库的 JsonParser 类提供了 parseString() 方法,用于将指定的 JSON 字符串解析成 JsonElements 对象。如果指定的字符串不是有效的 JSON 格式,则在解析的过程中会抛出 JsonSyntaxException 类型异常。 我们可以使用该方法来判断字符串是否为 JSON 格式,如果在解析过程中出现错误,说明指定的字符串不是有效的 JSON...
Java中Date类型与LocalDate或LocalDateTime相互转换
在 Java 中,Date 类型是表示日期和时间的类,而 LocalDate 和 LocalDateTime 是从 Java 8 开始引入的新日期时间 API 中的类。为了在不同的 API 之间进行转换,我们可以使用一些简单的方法。下面我们来详细介绍一下它们之间的相互转换。 Date类型转LocalDate或LocalDateTime类型要将 Date 类型转换为 LocalDate 或 LocalDateTime 类型,我们可以使用 Instant 类来辅助完成转换。Instant 类是 Java 8 中引入的用于表示时间戳的类。 使用以下方法将 Date 类型转换为 LocalDate:123Date date = new Date();Instant instant = date.toInstant();LocalDate localDate = instant.atZone(ZoneId.systemDefault()).toLocalDate(); 使用以下方法将 Date 类型转换为 LocalDateTime:123Date date = new...
关于Presto的LEFT JOIN,有一个很容易被忽略的点
LEFT JOIN 在 SQL 查询中是一种很常见的数据查询操作,其查询出来的数据是以左表为主表,保留左表的记录,如果右表没有匹配的记录,依然会返回左表的记录,此时右表的字段用 NULL 填充。 但是,在 Presto 中使用 LEFT JOIN 联结表查询,并需要对左表或右表进行过滤时,有一个特别容易忽略的地方是过滤条件的位置——对左表过滤时条件应写在 where 语句后,对右表过滤时条件应写在 on 后面。 如果对左表的过滤条件写在 on 后面,那么左表的每一行记录都会被保留,相当于没有过滤左表的数据。如果对右表的过滤条件写在 where 后面,那么 LEFT JOIN 查询出来的结果就后 JOIN 查询出来的结果一样,左表没有与右表匹配的记录也会被过滤。 下面通过一个例子来说明。 有两张表——用户信息表和用户地址表,表名分别为:tmp_user 和 tmp_addr,表中的记录如下: 表 tmp_user: user_id nickname 1 jack 2 johnson 3 marry 表...

Hive表重命名
表更名 SQL: 1alter table 旧表名 rename to 新表名; 执行该命令之后,表数据所在的位置(LOCATION)会移动到新的路径下。 例如,将表 test.dws_staff_kpi_day 重命名为 test.dws_staff_kpi_month。 在更名前,查看表 test.dws_staff_kpi_day 所在的位置: 1show create table test.dws_staff_kpi_day; 结果如下所示,可以看到表数据位于 hdfs://hdp-cluster/apps/hive/warehouse/test.db/dws_staff_kpi_day 目录下: 1234567891011121314151617181920CREATE TABLE `test.dws_staff_kpi_day`( `user_id` int COMMENT '用户ID', `phone` string COMMENT '手机号码', ...)COMMENT...

MySQL如何开启binlog日志
查看是否开启binlog日志连接 MySQL,执行以下命令: 1show variables like 'log_%'; 查询结果类似以下内容: Variable_name Value log_bin OFF log_bin_basename log_bin_index … 变量 log_bin 的值为 OFF,说明未开启 binlog 日志,若为 ON 说明已开启。 开启binlog日志若 MySQL 未开启 binlog 日志,可通过修改 MySQL 的配置文件 mysqld.cnf 启用 binlog 日志。 打开配置文件(注意:配置文件位置需改为你自己的存放位置): 1vim /etc/mysql/mysql.conf.d/mysqld.cnf 添加以下配置项: 123server_id = 20log_bin = mysql-binbinlog_format = ROW 保存修改内容,并重新启动 MySQL 使修改后的配置项生效,如使用 service...
Lightweight Asynchronous Snapshots for Distributed Dataflows
Author皇家理工学院 Paris Carbone1 Gyula Fora ´2 Stephan Ewen3 Seif Haridi1,2 Kostas Tzoumas31KTH Royal Institute of Technology - {parisc,haridi}@kth.se2Swedish Institute of Computer Science - {gyfora, seif}@sics.se3Data Artisans GmbH - {stephan, kostas}@data-artisans.com AbstractDistributed stateful stream processing enables the deployment and execution of large scale continuous omputations in the cloud, targeting both low latency and high throughput. One of the most fundamental challenges of this...
【Elasticsearch】Query DSL查询指定字段值为null的文档
Hey,大家好!我是 Elasticsearch 新手。我想知道如何通过 Query DSL 找出指定字段值为 null 的文档。 以下是我索引(索引名:class_info_v22002,用来存放班级信息)创建的 DSL: 123456789101112131415161718192021PUT class_info_v22002{ "settings": { "refresh_interval": "1s", "number_of_replicas": 1, "number_of_shards": 3 }, "mappings": { "properties": { "class_id": { "type": "integer" }, ...

Elasticsearch使用Query DSL批量写数据至索引报json_e_o_f_exception异常
我在 Kibana 的开发工具页面中使用 Query DSL 给索引批量添加数据时,出现了 json_e_o_f_exception 异常。 重现步骤如下: 创建索引 DSL: 12345678910111213141516171819202122232425262728PUT user_info_v202210120517219 { "settings": { "refresh_interval": "1s", "number_of_replicas": 1, "number_of_shards": 5 }, "mappings": { "properties": { "user_id": { "type": "integer" }, ...
运行第一个Flink应用
准备工作 基于 UNIX 环境 如果使用的是 Windows 环境,可以安装虚拟机软件(如 VMware Workstation Pro)并配置一个 Linux 系统(如 CentOS 8,Ubuntu 等)的虚拟机,也可以安装 Cygwin( 一个 Windows 下的 Linux 环境),或者配置 WSL (Windows Subsystem for Linux, Windows 10 中新加的功能)。 这里运行环境为 Windows 10 的 Linux 子系统: 1234➜ /opt cat /proc/versionLinux version 4.4.0-19041-Microsoft (Microsoft@Microsoft.com) (gcc version 5.4.0 (GCC) ) #488-Microsoft Mon Sep 01 13:43:00 PST 2020➜ /opt cat /etc/issueUbuntu 20.04.4 LTS \n \l 安装 Java 8 1234➜ /opt java -versionjava version...
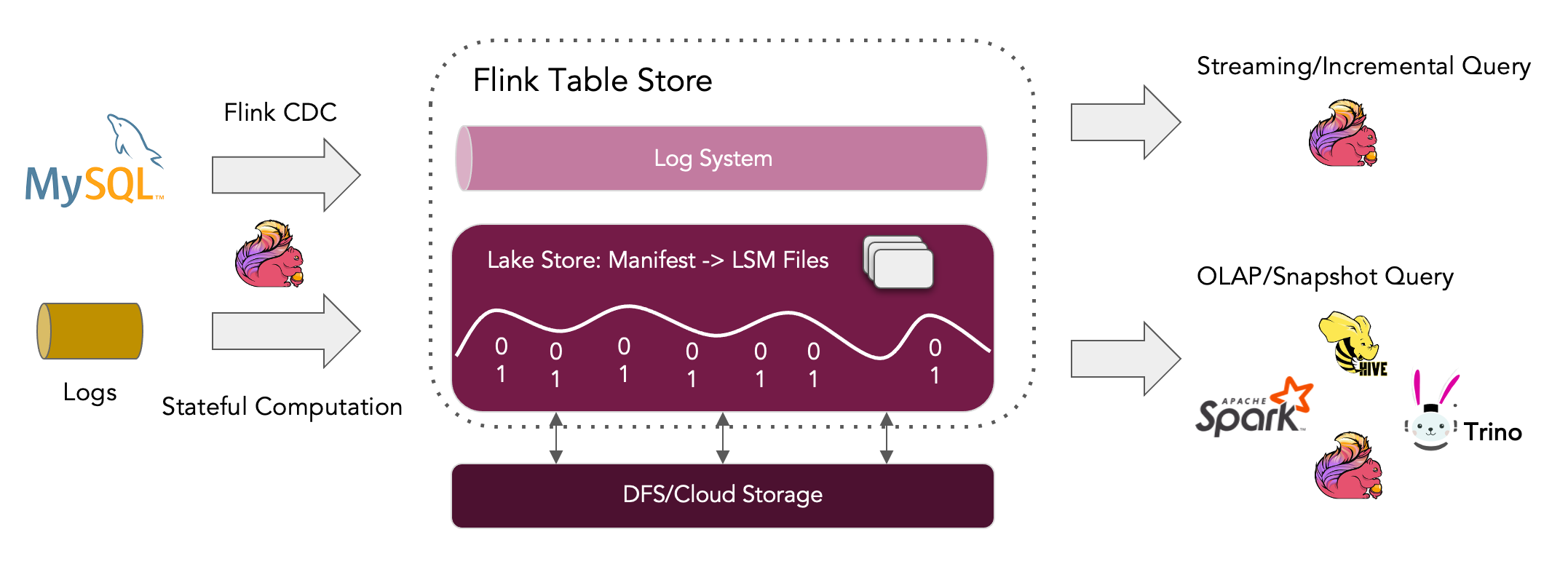
Apache Flink Table Store 快速入门
本文通过一个示例来简要介绍如何使用 Apache Flink Table Store。 步骤一:下载 Flink 注意:Flink Table Store 仅从 Flink 1.14 开始支持。 本示例使用的是 Flink 1.15.2 版本,使用 wget 下载: 1wget https://dlcdn.apache.org/flink/flink-1.15.2/flink-1.15.2-bin-scala_2.12.tgz 下载完成之后,解压文件: 1tar -xzf flink-1.15.2-bin-scala_2.12.tgz 本示例中,flink 的安装目录为 /mnt/d/flink-1.15.2 。为便于本文的后续说明,这里使用 ${FLINK_HOME} 代指 flink 的安装目录。 解压后的文件目录如下: 12345678910111213➜ flink-1.15.2 lltotal 616K-rwxrwxrwx 1 root root 12K Aug 17 20:10 LICENSE-rwxrwxrwx 1 root root 600K Aug 18...
Apache Flink Table Store——流批一体存储
Flink Table Store 面向更新场景的 OLAP 应用。作为流批统一存储,在 Flink 中为流式处理和批处理构建动态表,支持实时流式更新/删除变更日志摄取、实时流消费和高性能数据查询。当大量更新数据(如 MySQL 的 binlog 日志)写入 Flink Table Store 后,Flink Table Store 后台会根据主键来合并数据,默认保留最新变更后的数据。Flink Table Store 目前仍处于 beta 状态,正在快速发展,不建议直接在生产环境中使用。 出现背景在过去的几年里,得益于众多的贡献者和用户,Apache Flink 已经成为最好的分布式计算引擎之一,尤其是在大规模有状态流处理方面。然而,当试图深入了解实时数据时,仍然面临着一些挑战。在这些挑战中,一个突出的问题是缺乏满足所有计算模式的存储。 到目前为止,为了不同目的部署几个存储系统来使用 Flink 是很常见的。一个典型的部署是用于流处理的消息队列、用于批处理和即席查询的可扫描文件系统/对象存储、以及用于查找的 K-V...