
Ollama Core Concepts
Ollama is a localized machine learning framework designed for various natural language processing (NLP) tasks. It focuses on model loading, inference, and generation, making it easy for users to interact with large pre-trained models deployed locally.
Models
Models are the heart of Ollama. These are pre-trained machine learning models capable of performing tasks like text generation, summarization, sentiment analysis, and dialogue generation. Ollama supports a wide range of popular pre-trained models, including:
- Deepseek-v3: A large language model by DeepSeek, specialized in text generation.
- LLama2: A large language model by Meta, designed for text generation.
- GPT: OpenAI’s GPT series, suitable for dialogue generation, text reasoning, and more.
- BERT: A model for sentence understanding and question-answering systems.
- Custom Models: Users can upload and use their own custom models for inference.
Key Features of Models:
- Inference: Generating output based on user input.
- Fine-tuning: Adapting pre-trained models to specific tasks or domains using custom datasets.
Models are typically neural networks with millions (or billions) of parameters, trained on vast amounts of text data to learn language patterns and perform efficient reasoning.
Supported Models:
Ollama’s library of supported models can be accessed here: Ollama Model Library.
Click on the model to view the download command:
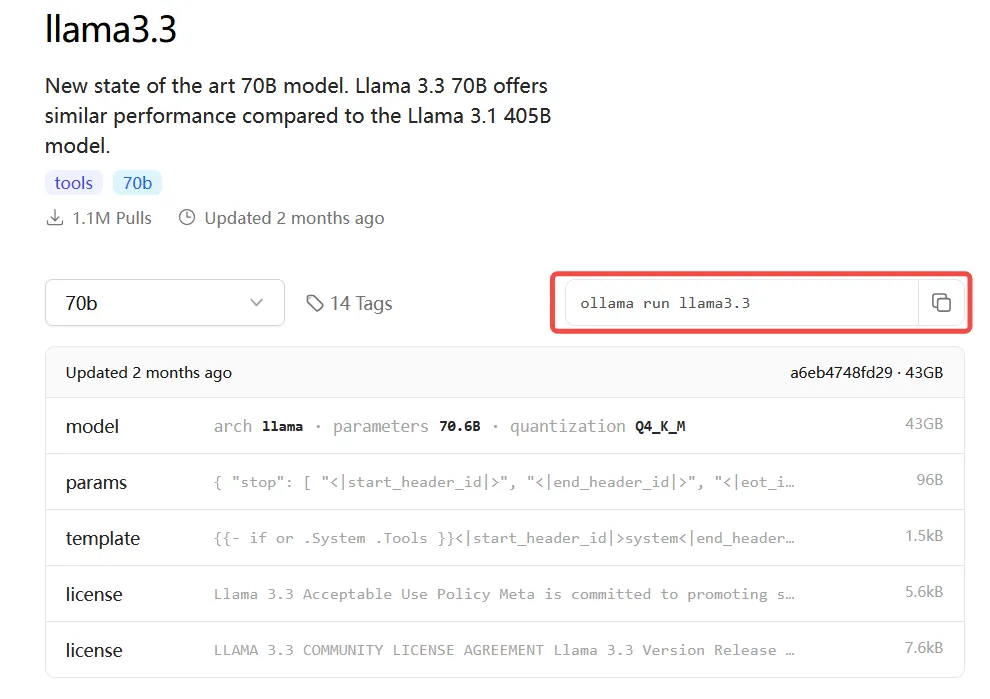
Below are some examples of models and their download commands:
| Model | Parameters | Size | Download Command |
|---|---|---|---|
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| DeepSeek-R1 | 70B | 43GB | ollama run deepseek-r1:70b |
| DeepSeek-R1 | 32B | 20GB | ollama run deepseek-r1:32b |
| DeepSeek-R1 | 14B | 9.0GB | ollama run deepseek-r1:14b |
| DeepSeek-R1 | 8B | 4.9GB | ollama run deepseek-r1:8b |
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1:7b |
| DeepSeek-R1 | 1.5B | 1.1GB | ollama run deepseek-r1:1.5b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
Tasks
Ollama supports a variety of NLP tasks, each corresponding to different use cases for the models. Key tasks include:
- Chat Generation: Generating natural dialogue responses in conversations.
- Text Generation: Creating natural language text based on prompts (e.g., articles, stories).
- Sentiment Analysis: Determining the emotional tone of a text (positive, negative, neutral).
- Text Summarization: Condensing long texts into concise summaries.
- Translation: Translating text between languages.
Using Ollama’s command-line tools, users can specify tasks and load appropriate models to achieve their goals.
Inference
Inference is the process of feeding input into a trained model to generate output. Ollama provides user-friendly command-line tools and APIs, allowing users to quickly input text and receive results.
How Inference Works:
- Input: The user provides text input, such as a question, prompt, or dialogue.
- Model Processing: The model processes the input using its neural network to generate relevant output.
- Output: The model returns the generated text, which could be a response, article, translation, etc.
Ollama’s API and CLI make it simple to interact with local models and perform inference tasks efficiently.
Fine-tuning
Fine-tuning involves further training a pre-trained model on domain-specific data to improve its performance on specific tasks or domains. Ollama supports fine-tuning, enabling users to customize models using their own datasets.
Fine-tuning Process:
- Prepare Dataset: Gather and format domain-specific data (e.g., text files or JSON).
- Load Pre-trained Model: Select a suitable pre-trained model (e.g., LLama2 or GPT).
- Train: Fine-tune the model using the custom dataset to adapt it to the target task.
- Save and Deploy: Save the fine-tuned model for future use and deploy it as needed.
Fine-tuning helps models achieve higher accuracy and efficiency in specialized tasks.