
Apache Paimon | 概述
Apache Paimon(孵化中)是一个流式数据湖平台,支持高速数据摄取、变化数据跟踪和高效的实时分析。
架构
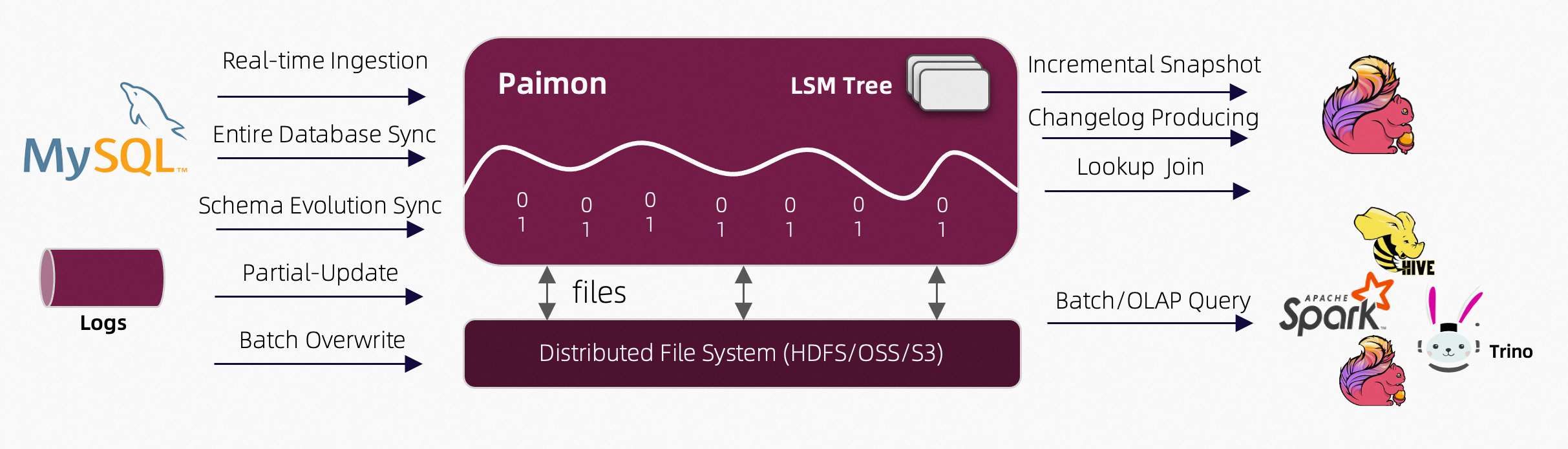
如上面的架构图所示:
读/写:Paimon 支持以多种方式读/写数据和执行 OLAP 查询。
- 对于读取,它支持消费
- 历史快照(批处理模式)的数据,
- 从最新偏移量(流处理模式)读取数据,或者
- 以混合方式读取增量快照。
- 对于写入,它支持从数据库的变化日志(CDC)中进行流式同步,或从离线数据中批量插入/覆盖。
生态系统:除了 Apache Flink 之外,Paimon 还支持其他计算引擎的读取,如 Apache Hive、Apache Spark 和 Trino。
内部原理:Paimon 在文件系统/对象存储中存储列式文件,并使用 LSM 树结构来支持大量数据更新和高性能查询。
统一存储
对于像 Apache Flink 这样的流引擎,通常有三种类型的连接器:
- 消息队列,如 Apache Kafka,用于管道的源头和中间阶段,以确保延迟在秒级内。
- OLAP 系统,如 Clickhouse,以流的方式接收处理后的数据,并为用户的临时查询提供服务。
- 批量存储,如 Apache Hive,支持传统批处理的各种操作,包括
INSERT OVERWRITE。
Paimon 提供了表的抽象化。它的使用方式与传统数据库没有区别:
- 在批处理执行模式下,它就像一个 Hive 表,支持 Batch SQL 的各种操作。查询它可以看到最新的快照。
- 在流式执行模式下,它的行为就像一个消息队列。查询它的行为就像从一个历史数据永不过期的消息队列中查询一个流变化日志。
(END)
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2023-09-06
Apache Paimon 0.5正式发布
Apache Paimon 0.5.0-incubating 版本终于在今天正式发布了。有近 100 位贡献者参与了此版本的开发,共完成了 500 多次代码提交,为社区带来了许多令人兴奋的新功能和改进。 该版本的主要亮点功能如下: CDC 数据入湖的功能已经成熟。 引入了标签的概念,为离线数据仓库提供不可变视图。 主键表的动态桶模式已投入生产。 引入仅追加模式可扩展表,以取代 Hive 表。 CDC摄入Paimon 支持多种方式将数据导入 Paimon 表,并支持模式演化。在 0.5 版本中,新增了许多新功能,包括: MySQL 数据表同步 支持将分片数据同步到一个 Paimon 表中。 支持将所有字段类型映射为字符串。 MySQL 数据库同步 支持合并多个数据库中的多个分片数据。 支持 --mode combined 模式,将所有表整合到一个统一的数据汇中进行同步,并支持在不重启作业的情况下同步新增的表。 从 Kafka 同步数据表 将 Kafka 主题里的数据表同步到 Paimon 表中。 支持 Canal 和 OGG 格式。 从 Kafka...
2023-09-11
Apache Paimon 0.5版本震撼发布:数据导入、查询性能再升级
昨日,Apache Paimon 0.5.0-incubating 版本正式发布。这个版本是在近 100 位贡献者的共同努力下完成的,共提交了 500 多次代码改进,为社区带来了许多令人兴奋的新功能和改进。 其中的亮点之一是 CDC(Change Data Capture)数据入湖的功能已经成熟。在 0.5 版本中,引入了标签的概念,为离线数据仓库提供了不可变视图。此外,主键表的动态桶模式也已经投入生产,并引入了仅追加模式可扩展表来取代 Hive 表。 Paimon 支持多种方式将数据导入 Paimon 表,并且支持模式演化。在 0.5 版本中,新增了许多新功能,例如 MySQL 同步表和数据库、Kafka 同步表和数据库以及 MongoDB 同步集合和数据库。 主键表可以通过在创建表的 DDL(数据定义语言)中指定主键来创建,它接受插入、更新或删除记录操作。而动态桶(Dynamic Bucket)模式是通过将 'bucket' 参数设置为 '-1' 来实现的,Paimon...
2023-06-10
Apache Paimon | 基本概念
快照(Snapshot)快照捕获了一个表在某个时间点上的状态。用户可以通过最新的快照来访问一个表的最新数据。通过时间旅行,用户也可以通过较早的快照访问表的先前状态。 分区(Partition)Paimon 采用了与 Apache Hive 相同的分区概念来分离数据。 分区是一种可选的方式,可以根据特定列的值(如日期、城市和部门等)将表划分为相关部分。每个表可以有一个或多个分区键来标识一个特定的分区。 通过分区,用户可以高效地对表中的某一记录切片进行操作。有关如何将文件划分为多个分区的详细信息,请参见文件布局。 如果定义了主键,分区键必须是主键的一个子集。 桶(Bucket)非分区的表或分区表中的分区会被细分为桶,以便为数据提供额外的结构,这可用于更有效的查询。 一个桶的范围是由记录中的一个或多个列的哈希值决定的。用户可以通过提供 bucket-key 选项来指定桶的列。如果没有指定 bucket-key...
2023-06-10
Apache Paimon | 主键表
Changelog 表是创建表时的默认表类型。用户可以插入、更新或删除表中的记录。 主键由一列或多列组成,其值能唯一地标识表中的每一行记录。Paimon 强制对数据进行排序,这意味着系统将对每个桶内的主键进行排序。利用这个特性,用户可以通过在主键上添加过滤条件来实现高性能。 通过在变更日志表上定义主键,用户可以获得以下功能。 合并引擎当 Paimon 接收器(sink)收到具有相同主键的两条或更多记录时,它将把这些记录合并成一条记录以保持主键的唯一性。通过指定 merge-engine 表属性,用户可以选择如何合并记录。 在 Flink SQL TableConfig 中始终将 table.exec.sink.upsert-materialize 设置为NONE,sink upsert-materialize 可能会导致奇怪的行为。当输入乱序时,建议使用 Sequence Field 进行乱序校正。 去重(Deduplicate)deduplicate 合并引擎是默认的合并引擎。Paimon 只会保留最新的记录,并丢弃具有相同主键的其他记录。 具体来说,如果最新的记录是一条...
2023-06-10
Apache Paimon | 仅追加表(Append Only 表)
如果一个表没有定义主键,那么它默认是一个 append-only 表。 你只能向表中插入完整的记录。不支持删除或更新,也不能定义主键。这种类型的表适用于不需要更新的用例(例如日志数据同步)。 分桶(Bucketing)你也可以为 Append-only 表定义桶的数量,见 Bucket。 建议设置 bucket-key 字段。否则,数据会按照整行进行散列,性能会很差。 压缩(Compaction)默认情况下,接收节点(sink 节点)将自动进行压缩以控制文件数量。以下选项控制压缩策略: Key 默认值 类型 描述 write-only false Boolean 如果设置为 true,压缩和快照过期将被跳过。此选项与专门的压缩作业一起使用。 compaction.min.file-num 5 Integer 对于文件集 [f_0,…,f_N],满足 sum(size(f_i)) >= targetFileSize...
2023-06-10
Apache Paimon | 外部日志系统
除了底层表文件的变更日志外,Paimon 的变更日志也可以存储在外部日志系统中,比如 Kafka,或者从外部日志系统中消费。通过指定 log.system 表属性,用户可以选择使用哪个外部日志系统。 如果选择使用外部日志系统,那么所有写入表文件中的记录也会写入日志系统。因此,流查询产生的变化会从日志系统读取,而不是表文件。 一致性保证默认情况下,日志系统中的变化要等到快照之后才对消费者可见,就像表文件一样。这种行为保证了精确一次的语义。也就是说,每条记录只被消费者看到一次。 但是,用户也可以指定表的属性 'log.consistency' = 'eventual',这样写进日志系统的变更日志就可以立即被消费者消费,而不用等待下一个快照。这种行为减少了变更日志的延迟,但由于可能发生的故障,它只能保证至少一次的语义(即,消费者可能会看到重复的记录)。 如果设置 'log.consistency' = 'eventual',为了获得正确的结果,Flink 中的 Paimon...