
Apache Flink 1.17 发版公告
本文翻译自 Apache Flink 社区博文——《Announcing the Release of Apache Flink 1.17》
Apache Flink PMC(项目管理委员会)很高兴地宣布发布 Apache Flink 1.17.0 版。Apache Flink 是领先的流处理标准,统一的流和批数据处理概念正被越来越多的公司成功采用。得益于我们优秀的社区和贡献者,Apache Flink 作为一项技术在不断发展壮大,并且仍然是 Apache 软件基金会中最活跃的项目之一。Flink 1.17 版本有 172 位贡献者热情参与,完成了 7 个 FLIP 和 600 多个问题,为社区带来了许多令人兴奋的新功能和改进。
迈向流式仓库
为了在流式仓库领域实现更高的效率,Flink 1.17 在批处理性能和流处理语义方面进行了大量改进。这些改进标志着朝创建更高效、更精简的数据仓库迈出的重要一步,使其能够实时处理大量数据。
对于批处理而言,此版本包含了多项新功能和改进:
- 流式仓库 API:FLIP-282 在 Flink SQL 中引入了新的删除和更新 API,该 API 仅在批处理模式下工作。像 Flink Table Store 这样的外部存储系统可以通过这个新的 API 实现行级修改。ALTER TABLE 语法得到了增强,包括添加/修改/删除列、主键和水印的能力,使用户更容易维护表的模式。
- 批处理执行改进:在 Flink 1.17 中,批处理工作负载的执行在性能、稳定性和可用性方面都得到了显著改进。在性能方面,通过策略和运算符优化,如新的连接重排序和自适应本地哈希聚合、Hive 聚合函数改进以及混合洗牌模式(Hybrid Shuffle Mode)增强,10T 数据集的 TPC-DS 性能提高了 26%。在稳定性方面,推测执行(Speculative Execution)现在支持所有运算符,并且自适应批处理调度器(Adaptive Batch Scheduler)对数据倾斜更加健壮。在易用性方面,批处理工作负载所需的调优工作得到了简化。混合洗牌模式现在是批处理模式的默认调度器。混合洗牌模式与推测执行和自适应批处理调度器兼容,并简化了各种配置。
- SQL 客户端/网关:Apache Flink 1.17 为 SQL 客户端引入了“网关模式”,允许用户向 SQL 网关提交 SQL 查询以获得增强功能。用户可以使用 SQL 语句来管理作业生命周期,包括显示作业信息和停止正在运行的作业。这为管理 Flink 作业提供了强大的工具。
流处理方面实现了以下功能和改进:
- 流式 SQL 语义:非确定性操作可能会带来错误的结果或异常,在流式 SQL 中这是一个有挑战性的问题。修复了不正确的优化计划和功能问题,并引入了 PLAN_ADVICE 实验性功能,以向 SQL 用户提供潜在的正确性风险和优化建议信息。
- 检查点改进:通用增量检查点改进提高了检查点过程的速度和稳定性,在 Flink 1.17 中,非对齐检查点在背压情况下的稳定性得到了改善,并且已经达到了生产就绪状态。用户可以在作业运行时通过新引入的触发检查点的 REST 接口来手动触发具有自定义检查点类型的检查点。
- 水印对齐增强:高效的水印处理直接影响事件时间应用程序的执行效率。在 Flink 1.17 中,FLIP-217 引入了一种改进的水印对齐方式,通过对源操作符内的分片进行数据发射对齐,从而更有效地协调源中的水印进度,从而减少下游操作符的过度缓冲,提高流作业执行的整体效率。
- 状态后端升级:FRocksDB 升级到 6.20.3-ververica-2.0 版本,为 RocksDBStateBackend 带来了改进,如在插槽之间共享内存,并且现在支持苹果芯片(如 Mac M1)。
批处理
作为一个统一的流和批处理数据引擎,Flink 在流处理领域尤为突出。为了提高其批处理能力,社区贡献者在 1.17 版本中投入了大量精力来改进 Flink 的批处理性能和生态系统。这使得用户可以更轻松地基于 Flink 构建流式仓库。
推测执行(Speculative Execution)
现在支持 Sink 的推测执行(Speculative Execution)。以前,为了避免不稳定或错误的结果,Sink 未启用推测执行。在 Flink 1.17 中,改进了 Sink 的上下文,使得 Sink(包括新的 Sink 和 OutputFormat Sink 在内)能够感知到尝试次数。有了尝试次数,即使多个尝试同时运行,Sink 也能够隔离同一子任务的不同尝试产生的数据。此外,还改进了 FinalizeOnMaster 接口,使得 OutputFormat Sink 可以查看哪些尝试已经完成,然后正确提交已写入的数据。一旦 Sink 能够很好地处理并发尝试,就可以实现装饰接口 SupportsConcurrentExecutionAttempts,从而允许对其进行推测执行。一些内置的 Sink 已经启用了推测执行,包括 DiscardingSink、PrintSinkFunction、PrintSink、FileSink、FileSystemOutputFormat 和 HiveTableSink。
推测执行的慢任务检测也得到了改进。以前,确定哪些任务较慢时只考虑任务的执行时间。现在还考虑了任务的输入数据量。执行时间较长但同时消耗更多数据的任务可能不被视为慢任务。这一改进有助于消除数据倾斜对慢任务检测的负面影响。
自适应批处理调度器(Adaptive Batch Scheduler)
Adaptive Batch Scheduler 现在默认用于批处理作业。该调度器可以根据每个作业任务处理的数据量自动确定适当的并行度。它也是唯一支持推测执行的调度器。
Adaptive Batch Scheduler 的配置得到了改进,更易于使用。用户不再需要显式地将全局默认并行度设置为 -1,就能自动决定并行度。相反,如果设置了全局默认并行度,那么在决定并行度时,全局默认并行度将被用作上限。Adaptive Batch Scheduler 配置选项的键名也已更名,以便更易于理解。
Adaptive Batch Scheduler 的功能也得到了改进。它现在支持根据细粒度的数据分布信息将数据均匀地分发给下游任务。不再需要并行度只能是 2 的幂次的限制,因此取消了这一限制。
混合洗牌模式(Hybrid Shuffle Mode)
本次发布中对混合洗牌模式进行了多项重要改进。
混合洗牌模式现在支持自适应批处理调度器(Adaptive Batch Scheduler)和推测执行(Speculative Execution)。
混合洗牌模式现在支持在可能的情况下重复使用中间数据,这带来了显著的性能提升。
改进了稳定性,以避免在大规模生产中出现稳定性问题。
更多详细信息请参阅文档中的混合洗牌(Hybrid-Shuffle)部分。
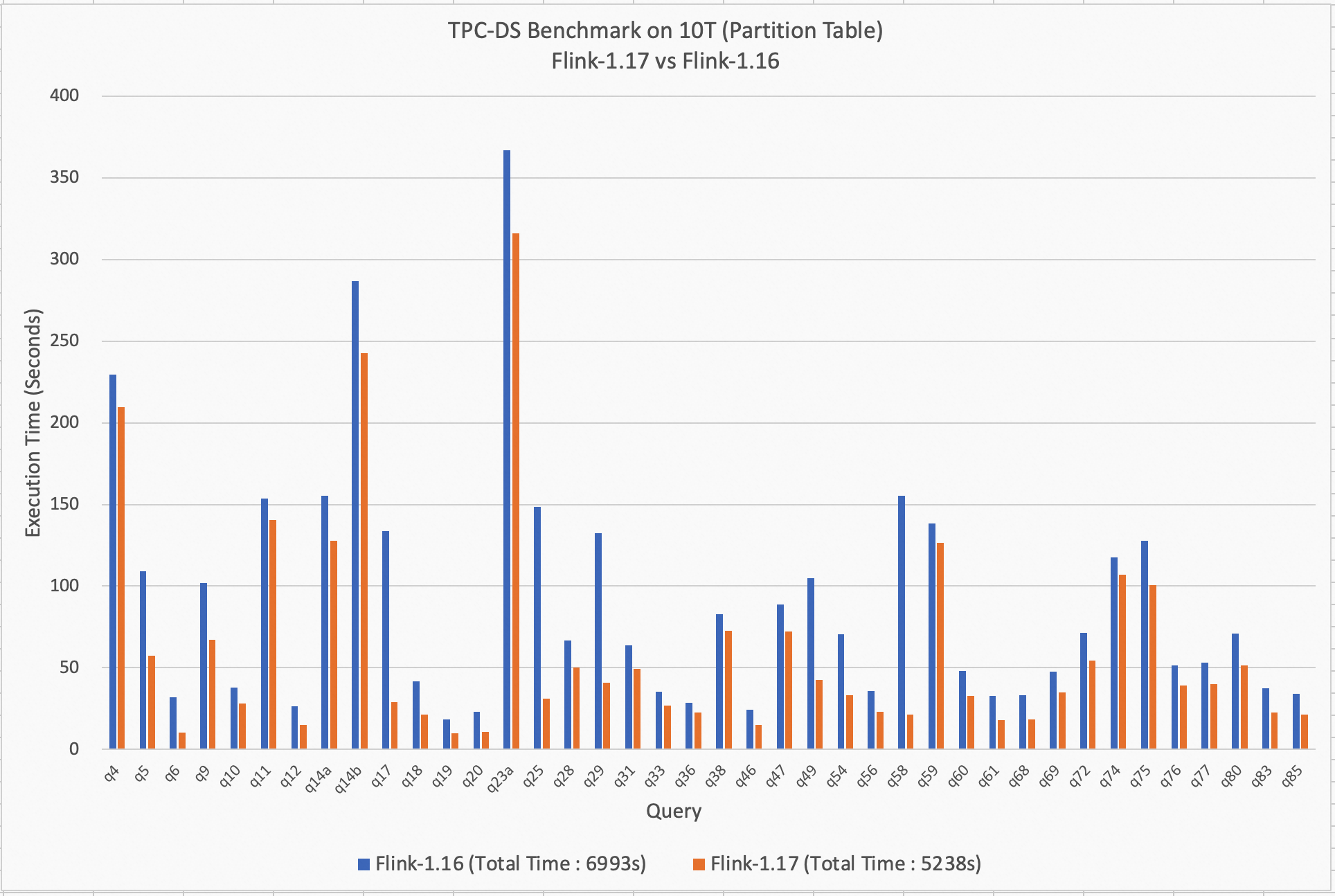
TPC-DS 基准
从 Flink 1.16 开始,批处理引擎的性能不断得到优化。在 Flink 1.16 中,引入了动态分区剪枝,但并非所有 TPC-DS 查询都可以被优化。在 Flink 1.17 中,该算法已得到改进,现在大多数 TPC-DS 结果都得到了优化。在 Flink 1.17 中,引入了一种动态规划连接重排算法,与先前的算法相比,它的工作效果更好,搜索空间更大。查询计划器可以根据查询中连接的数量自动选择适当的连接重排算法,因此用户无需关注连接重排算法。(注意:连接重排默认情况下是禁用的,运行 TPC-DS 时需要启用)。在算子层面上,引入了动态哈希局部聚合策略,它可以根据数据分布动态确定是否需要进行局部哈希聚合操作以提高性能。在运行时层面上,去除了一些不必要的虚拟函数调用,以加速执行速度。总之,在使用分区表的 10T 数据集上,与 Flink 1.16 相比,Flink 1.17 的性能提高了 26%。
SQL 客户端/网关(SQL Client / Gateway)
Apache Flink 1.17 为 SQL Client 引入了一项名为“网关模式”(gateway mode)的新功能,它允许 SQL Client 连接到远程网关,并像在嵌入式模式下一样提交 SQL 查询,从而增强了 SQL Client 的功能。这种新模式为用户在使用 SQL Gateway 时提供了更多的便利。
此外,SQL Client/SQL Gateway 现在还为通过 SQL 语句管理作业生命周期提供了新的支持。用户可以使用 SQL 语句显示存储在 JobManager 中的所有作业信息,并使用唯一的作业 ID 停止运行中的作业。有了这项新功能,SQL Client/Gateway 现在几乎具备了与 Flink CLI 相同的功能,成为管理 Flink 作业的又一强大工具。
SQL API
行级 SQL 删除和更新在现代大数据工作流中变得越来越重要。使用案例包括为遵守法规而删除一组行,为纠正数据而更新一组行等。许多流行的引擎(如 Trino 或 Hive)已经支持了这些功能。在 Flink 1.17 中,Flink 引入了新的删除和更新 API,该 API 以批处理模式工作,并暴露给连接器。现在,外部存储系统可以通过这个新 API 实现行级修改。此外,ALTER TABLE 语法还扩展了添加/修改/删除列、主键和水印的功能。这些增强功能为用户提供了根据自身需要维护表模式元数据的灵活性。
Hive 兼容性
Apache Flink 1.17 对 Hive 表 Sink 进行了改进,使其比以往更加高效。在以前的版本中,Hive 表 Sink 只支持流模式下的自动文件压缩,而不支持批处理模式。在 Flink 1.17 中,Hive 表 Sink 现在也能在批处理模式下自动压缩新写入的文件。这一功能可以大大减少小文件的数量。此外,为了通过 HiveModule 使用 Hive 内置函数,Flink 在 HiveModule 中引入了多个原生 Hive 聚合函数,包括 SUM/COUNT/AVG/MIN/MAX。这些函数可以使用基于哈希的聚合算子来执行,从而显著提高性能。
流处理
在 Flink 1.17 中,解决了流式 SQL 语义难点和正确性问题,优化了检查点性能,增强了水印对齐功能,扩展了流 FileSink 对 ABFS(Azure Blob Filesystem)的支持,并将 Calcite 和 FRocksDB 升级到了更新的版本。这些改进进一步增强了 Flink 在流处理领域的能力。
流式 SQL 语义
在正确性和语义增强方面,Flink 1.17 引入了实验性功能 PLAN_ADVICE,用于检测潜在的正确性风险并提供优化建议。例如,如果通过 EXPLAIN PLAN_ADVICE 检测到 NDU(非确定性更新)问题,优化器就会在物理计划末尾附加建议,然后将建议 ID 标记到相关操作的关系节点上,并建议用户相应地更新配置。通过向用户提供这些具体建议,优化器可以帮助用户提高查询结果的准确性和可靠性。
1 | == Optimized Physical Plan With Advice == |
PLAN_ADVICE 还能帮助用户提高查询的性能和效率。例如,当检测到 GroupAggregate 操作时,可将其优化为更高效的本地-全局聚合。通过向用户提供这种具体的优化建议,优化器能让用户轻松提高查询的性能和效率。
1 | == Optimized Physical Plan With Advice == |
此外,Flink 1.17 还解决了几个错误的计划优化问题,这些问题导致了 FLINK-29849、FLINK-30006 和 FLINK-30841 中报告的错误结果。
检查点改进
通用增量检查点(Generic Incremental Checkpoint,GIC)旨在提高检查点过程的速度和稳定性。WordCount 案例的部分实验结果如下所示。更多详情可参阅这篇博文。
表 1: 在 WordCount 案例中启用 GIC 后的优势

表 2:在 WordCount 案例中启用 GIC 后的代价

非对齐检查点(Unaligned Checkpoints,UC)显著提高了在背压情况下检查点的完成率。之前的 UC 实现会写入许多小文件,这可能会给 HDFS 的 namenode 带来高负载。本版本解决了这一问题,使 UC 在生产环境中更加可用。
在 1.17 版本中,提供了一个 REST API,用户可以在作业运行时使用自定义的检查点类型手动触发检查点。例如,对于使用增量检查点运行的作业,用户可以定期或手动触发全量检查点,以中断增量检查点链,避免引用很久以前的文件。
水印对齐支持
在早期的版本中,FLIP-182 提出了一种名为水印对齐(watermark alignment)的解决方案,用于解决事件时间应用中由于数据源不平衡造成的数据倾斜问题。然而,它有一个局限性,即源算子的并行度必须与分片数相匹配。这是因为,如果一个分片比另一个分片更快地发送数据,具有多个分片的源算子可能需要缓冲大量数据。为解决这一限制,Flink 1.17 引入了 FLIP-217,它增强了水印对齐功能,在考虑水印边界的同时,对源算子内各分片的数据发射进行对齐。这一增强功能可确保源算子中的水印进度更加协调,防止下游算子缓冲过多数据,并提高流作业的执行效率。
流 FileSink 扩展
在添加 ABFS 支持后,FileSink 现在能够在流模式下使用总共五种不同的文件系统: HDFS、S3、OSS、ABFS 和本地。这一扩展有效地涵盖了大多数主要文件系统,为用户提供了全面的选择范围和更高的通用性。
RocksDBStateBackend 升级
此版本将 FRocksDB 升级到了 6.20.3-ververica-2.0,为 RocksDBStateBackend 带来了改进:
- 支持在苹果 Silicon 芯片组上构建 FRocksDB Java,如 Mac M1 和 M2
- 通过避免昂贵的 ToString() 来提高压缩过滤器的性能
- 升级 FRocksDB 的 ZLIB 版本以避免内存崩溃
- 为 RocksJava 添加 periodic_compaction_seconds 选项
详情请参见 FLINK-30836。
此版本还将插槽(slot)之间共享内存的范围扩大到 TaskManager,这有助于在 TaskManager 中插槽内存使用不均衡的情况下提高内存效率。此外,经过调整后,它还能减少整体内存消耗,但会牺牲资源隔离性能。了解有关 state.backend.rocksdb.memory.fixed-per-tm 配置的更多信息。
Calcite 升级
Flink 1.17 将 Calcite 升级到 1.29.0 版本,以提高 Flink SQL 系统的性能和效率。Flink 1.16 使用的是 Calcite 1.26.0,该版本在 RexNode 简化方面存在严重问题,这是由 SEARCH 操作符引起的。如 CALCITE-4325 和 CALCITE-4352 中报告的那样,这会导致查询优化时产生错误数据。通过升级 Calcite 版本,Flink 可以在 Flink SQL 处理中充分利用其改进的性能和新特性。这解决了多个错误,并加快了查询处理时间。
其他
PyFlink
Flink 1.17 版本对 Apache Flink 的 Python 接口 PyFlink 进行了更新。值得注意的改进包括对 Python 3.10 的支持,以及在 Apple Silicon 芯片组上(如 Mac M1 和 M2 计算机)的执行能力。此外,该版本还包括了一些小的优化,增强了 Java 和 Python 进程之间的跨进程通信稳定性,通过字符串来指定 Python UDF 的数据类型以提高可用性,并支持在 Python UDF 中访问作业参数。该版本主要关注改进 PyFlink 的功能和可用性,而不是引入新的主要特性。但是,这些增强功能有望改善用户体验,促进高效的数据处理。
每日性能基准测试
在 Flink 1.17 中,每日性能监控已经集成到 #flink-dev-benchmarks Slack 频道中。这个功能对于快速发现回归问题并确保代码质量非常重要。一旦通过 Slack 频道或 speed center 发现了回归问题,开发人员可以参考基准测试的 Wiki 中提供的指导来有效解决问题。这个功能有助于社区采取主动的方式来确保系统性能,从而实现更好的产品并提高用户满意度。
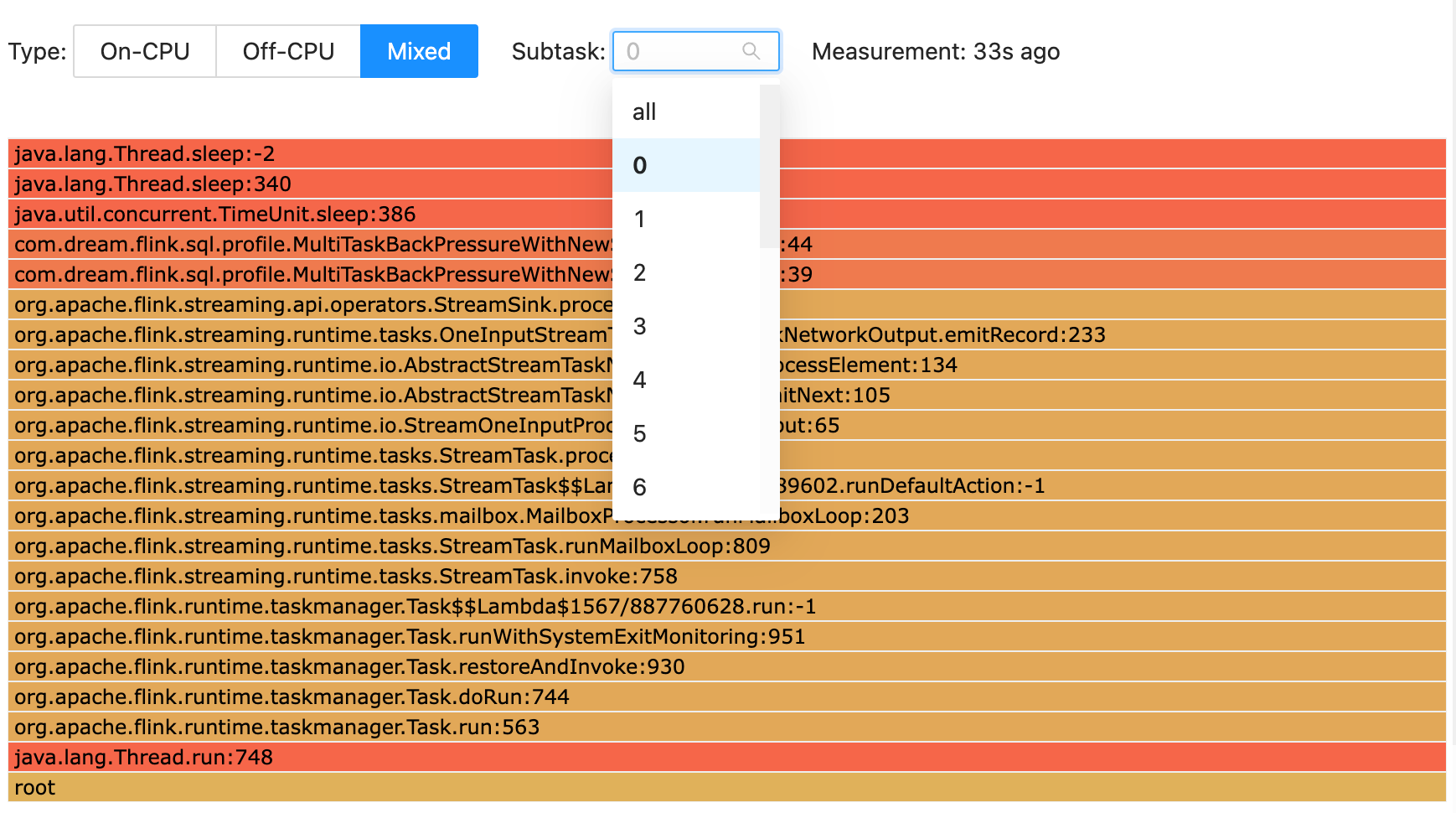
子任务级火焰图
从 Flink 1.17 开始,Flame Graph 提供了对任务级别的“向下钻取”可视化功能,使用户能够更详细地了解任务的性能。与 Flame Graph 以前的版本相比,这一功能有了重大改进,因为它使用户能够选择感兴趣的子任务并查看相应的火焰图。通过这种方式,用户可以确定其任务可能遇到性能问题的特定区域,并采取措施加以解决。这将大大提高数据处理管道的整体效率和有效性。
通用授权令牌支持
之前,Flink 支持 Kerberos 认证和基于 Hadoop 的令牌。通过完成 FLIP-272,Flink 的授权令牌框架被泛化,使其与认证协议无关。这将允许贡献者在未来添加对非 Hadoop 兼容框架的支持,在这些框架中,身份验证协议并非基于 Kerberos。此外,FLIP-211 的实现改善了 Flink 与 Kerberos 的交互:它减少了在 Flink 中交换授权令牌所需的请求数量。
升级注意事项
Flink 社区尽力确保升级过程尽可能无缝。然而,在升级到 1.17 版时,某些变化可能会要求用户对程序的某些部分进行调整。请参阅版本说明,了解在升级过程中需要进行的调整和需要检查的问题的完整列表。
贡献者名单
Apache Flink 社区向所有促成此版本发布的贡献者表示感谢:
Ahmed Hamdy, Aitozi, Aleksandr Pilipenko, Alexander Fedulov, Alexander Preuß, Anton Kalashnikov, Arvid Heise, Bo Cui, Brayno, Carlos Castro, ChangZhuo Chen (陳昌倬), Chen Qin, Chesnay Schepler, Clemens, ConradJam, Danny Cranmer, Dawid Wysakowicz, Dian Fu, Dong Lin, Dongjoon Hyun, Elphas Toringepi, Eric Xiao, Fabian Paul, Ferenc Csaky, Gabor Somogyi, Gen Luo, Gunnar Morling, Gyula Fora, Hangxiang Yu, Hong Liang Teoh, HuangXingBo, Jacky Lau, Jane Chan, Jark Wu, Jiale, Jin, Jing Ge, Jinzhong Li, Joao Boto, John Roesler, Jun He, JunRuiLee, Junrui Lee, Juntao Hu, Krzysztof Chmielewski, Leonard Xu, Licho, Lijie Wang, Mark Canlas, Martijn Visser, MartijnVisser, Martin Liu, Marton Balassi, Mason Chen, Matt, Matthias Pohl, Maximilian Michels, Mingliang Liu, Mulavar, Nico Kruber, Noah, Paul Lin, Peter Huang, Piotr Nowojski, Qing Lim, QingWei, Qingsheng Ren, Rakesh, Ran Tao, Robert Metzger, Roc Marshal, Roman Khachatryan, Ron, Rui Fan, Ryan Skraba, Salva Alcántara, Samrat, Samrat Deb, Samrat002, Sebastian Mattheis, Sergey Nuyanzin, Seth Saperstein, Shengkai, Shuiqiang Chen, Smirnov Alexander, Sriram Ganesh, Steven van Rossum, Tartarus0zm, Timo Walther, Venkata krishnan Sowrirajan, Wei Zhong, Weihua Hu, Weijie Guo, Xianxun Ye, Xintong Song, Yash Mayya, YasuoStudyJava, Yu Chen, Yubin Li, Yufan Sheng, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, Zhenqiu Huang, Zhu Zhu, ZmmBigdata, bzhaoopenstack, chengshuo.cs, chenxujun, chenyuzhi, chenyuzhi459, chenzihao, dependabot[bot], fanrui, fengli, frankeshi, fredia, godfreyhe, gongzhongqiang, harker2015, hehuiyuan, hiscat, huangxingbo, hunter-cloud09, ifndef-SleePy, jeremyber-aws, jiangjiguang, jingge, kevin.cyj, kristoffSC, kurt, laughingman7743, libowen, lincoln lee, lincoln.lil, liujiangang, liujingmao, liuyongvs, liuzhuang2017, luoyuxia, mas-chen, moqimoqidea, muggleChen, noelo, ouyangwulin, ramkrish86, saikikun, sammieliu, shihong90, shuiqiangchen, snuyanzin, sunxia, sxnan, tison, todd5167, tonyzhu918, wangfeifan, wenbingshen, xuyang, yiksanchan, yunfengzhou-hub, yunhong, yuxia Luo, yuzelin, zhangjingcun, zhangmang, zhengyunhong.zyh, zhouli, zoucao, 沈嘉琦
(END)