
了解Filebeat:采集、转发和汇总日志的轻量型解决方案
Filebeat 是什么?
Filebeat 是基于 libbeat 框架开发的一款开源的轻量型日志采集器,专为快速收集和传输多种来源的日志数据而设计。它可以从安全设备、云、容器、主机或 OT 等多种数据源采集日志,并提供一种轻量型的方法,用于转发和汇总日志与文件。
Filebeat 有什么特点?
1、Filebeat 支持从多种数据源收集数据,例如安全设备、云服务、容器、主机或 OT等。
2、Filebeat 具有性能稳定、支持容错机制的特点。如果在未来某个时刻 Filebeat 因为某种原因中断,恢复正常后,它可以从中断前停止的位置继续读取并转发日志行。
3、Filebeat 支持背压机制。这意味着,如果 Filebeat 发送日志数据的速率超过接收端(例如 Logstash、Elasticsearch等)处理数据的速率,接收端会向 Filebeat 发出信号,要求 Filebeat 减慢发送速度,以避免 Filebeat 收集的数据因内存不足而被丢弃。一旦接收端处理数据的速率跟上,Filebeat 就会恢复到原来的步伐并继续传输数据。
4、Filebeat 提供了一组预先构建的模块,用于简化常见格式的日志的收集、解析和可视化,比如 Nginx Web 服务器的访问日志等。
5、Filebeat 是 Elastic Stack 的一部分,可以与 Logstash、Elasticsearch 和 Kibana 无缝协作。无论是想要使用 Logstash 对日志和文件进行转换或增强,还是想在 Elasticsearch 中进行一些分析,或者是在 Kibana 中构建和共享仪表板,Filebeat 都能轻松地将数据发送至最关键的地方。
Filebeat 如何工作?
Filebeat 作为代理安装在服务器上,它会监控指定的日志文件或位置,收集日志事件,并将它们转发到指定的输出上。
当我们启动 Filebeat 进程时,它会根据我们的配置信息,启动一个或多个输入,去查找指定位置下的日志文件。对于每个查找到的日志文件,Filebeat 都会启动一个与之对应的采集器,读取文件中的新增日志数据,并将它们发送给 libbeat。libbeat 会先聚合这些日志数据,然后再将聚合后的数据发送到我们指定的输出上,例如 Elasticsearch、Logstash、Kafka 或 Redis 等。
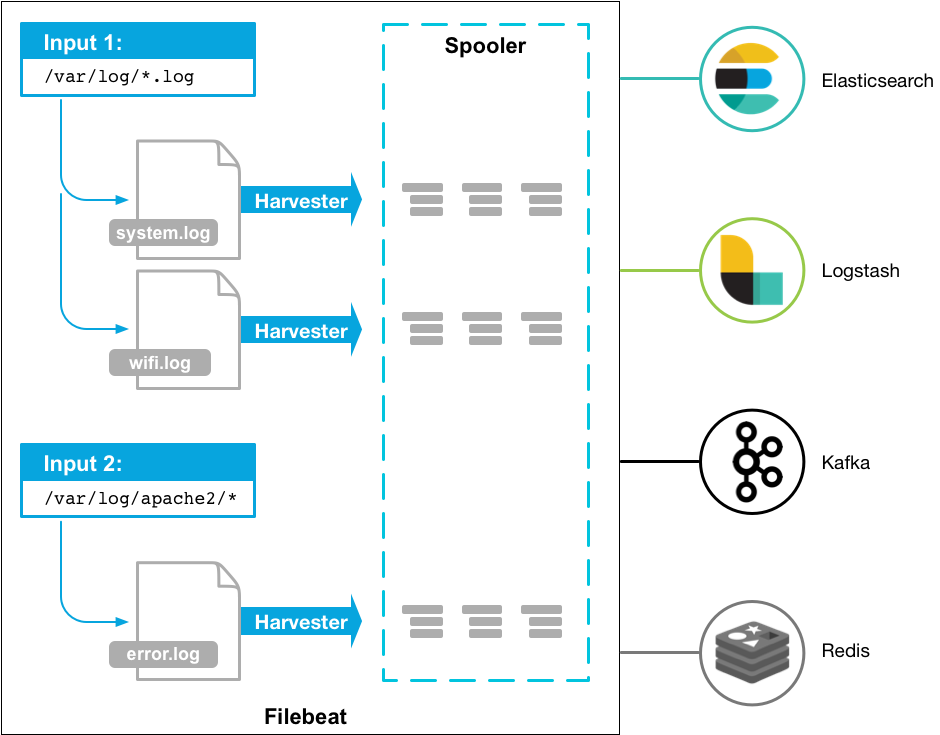
以上图为例,我们配置 Filebeat 从两个位置采集日志数据:
- 从 /var/log 目录下采集文件扩展名为 log 的文件;
- 从 /var/log/apache2 目录下采集所有文件。
接着,启动 Filebeat 进程,Filebeat 会启动两个输入来查找日志文件:
- 输入 1(Input 1)查找 /var/log 目录下文件扩展名为 log 的文件;
- 输入 2(Input 2)查找 /var/log/apache2 目录下所有文件。
其中,在 /var/log 当前目录下找到了两个符合条件的日志文件——system.log 和 wifi.log。Filebeat 会启动两个采集器,分别采集这两个日志文件的新增日志数据。在 /var/log/apache2 目录下只有一个 error.log 日志文件,Filebeat 同样也会启动一个采集器来采集该文件新增的数据。这三个采集器会把采集到的日志数据发送给 libbeat。libbeat 会对收到的日志数据进行聚合,然后再根据我们的配置信息,将聚合后的日志数据发送到 Elasticsearch、Logstash、Kafka 或 Redis 等输出上。
(END)