Apache Flink Table Store——流批一体存储
Flink Table Store 面向更新场景的 OLAP 应用。作为流批统一存储,在 Flink 中为流式处理和批处理构建动态表,支持实时流式更新/删除变更日志摄取、实时流消费和高性能数据查询。当大量更新数据(如 MySQL 的 binlog 日志)写入 Flink Table Store 后,Flink Table Store 后台会根据主键来合并数据,默认保留最新变更后的数据。
Flink Table Store 目前仍处于 beta 状态,正在快速发展,不建议直接在生产环境中使用。
出现背景
在过去的几年里,得益于众多的贡献者和用户,Apache Flink 已经成为最好的分布式计算引擎之一,尤其是在大规模有状态流处理方面。然而,当试图深入了解实时数据时,仍然面临着一些挑战。在这些挑战中,一个突出的问题是缺乏满足所有计算模式的存储。
到目前为止,为了不同目的部署几个存储系统来使用 Flink 是很常见的。一个典型的部署是用于流处理的消息队列、用于批处理和即席查询的可扫描文件系统/对象存储、以及用于查找的 K-V 存储。但这种架构由于复杂性和异构性,在数据质量和系统维护方面都提出了挑战。正成为影响 Apache Flink 流批统一端到端用户体验的一大问题。
而 Flink Table Store 的目标就是解决上述问题,将 Flink 的能力从计算扩展到存储领域,以便为用户提供更好的端到端体验。
核心能力
Flink Table Store 旨在提供统一的存储抽象,让用户不必自己构建混合存储。具体来说,Flink Table Store 提供以下核心能力:
- 支持大型数据集的存储,并允许在批处理和流模式下进行读/写;
- 支持毫秒级延迟的流式查询;
- 支持秒级延迟 Batch/OLAP 查询;
- 默认情况下,流消费支持增量快照。所以用户不需要自己解决组合不同存储带来的问题。
主要特点
作为一种新型的可更新数据湖,Flink Table Store 具有以下特点:
- 大吞吐量数据摄取,同时提供良好的查询性能。
- 具有主键过滤器的高性能查询,最快 100 毫秒。
- Lake Storage 上提供流式读取,Lake Storage 也可以与 Kafka 集成,提供秒级流式读取。
演进过程
在早先发布的 0.1.0 预览版,用户可以使用 Flink 将数据写入到 Flink Table Store 中,既可以通过流式传输从数据库中捕获的更新日志,也可以通过从数据仓库等其他存储中批量加载数据。
用户可以使用 Flink 以不同的方式查询 Flink Table Store,包括流式查询和 Batch/OLAP 查询。还值得注意的是,用户也可以使用其他引擎(例如 Apache Hive)从 Flink Table Store 中查询。
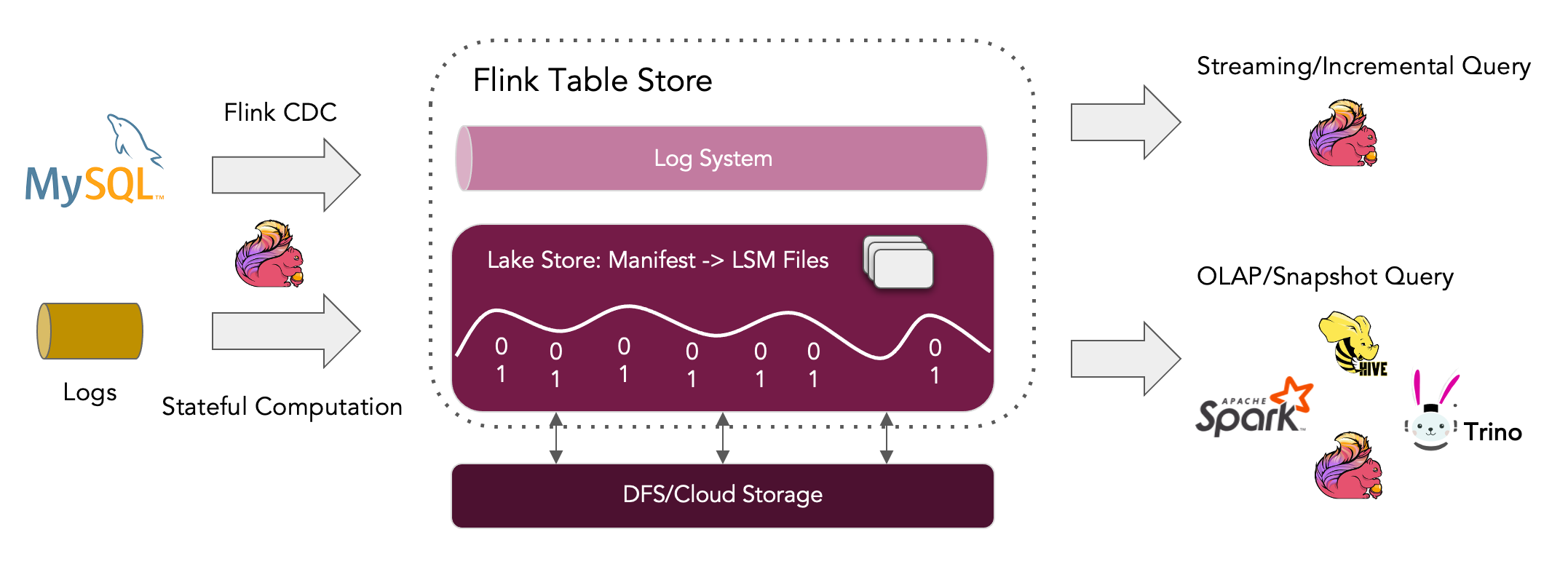
在底层,Flink Table Store 使用混合存储架构,使用 Lake Store 存储历史数据,使用 Queue 系统(目前支持 Apache Kafka 集成)存储增量数据。它为混合流式读取提供增量快照。
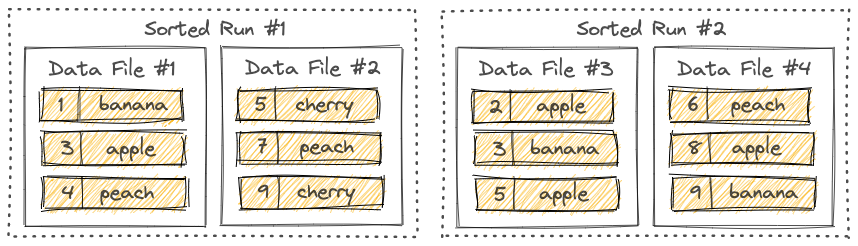
Flink Table Store 的 Lake Store 将数据作为列文件存储在文件系统/对象存储上,并使用 LSM 结构来支持大量的数据更新和高性能查询。
目前,Flink Table Store 发布了 0.2.0 版本。该版本主要包含以下四个值得关注的新特性:
- 引入自己的目录(Catalog),并支持自动同步到 Hive Metastore;
- 增加对 Flink 1.14 的支持,并支持多个计算引擎(Spark、Hive、Trino)的读取操作;
- 支持 append-only 表特性;
- 支持可调整存储桶数量。
在即将发布的 0.3.0 版本中,可以期待(至少)以下功能:
- 支持流式变更日志并发写入,Compaction 隔离;
- Aggregation Table,用于构建物化视图;
- 为部分更新/聚合表生成变更日志;
- Full Schema Evolution 支持删除列和重命名列;
- 查找支持 Flink 维度连接。
内容来源
https://flink.apache.org/news/2022/08/29/release-table-store-0.2.0.html
https://flink.apache.org/news/2022/05/11/release-table-store-0.1.0.html
(END)