
生产环境MySQL慢查询问题定位
本文根据实际项目经验,详细描述 MySQL 慢查询问题的发现及排查解决过程。在不影响读者阅读理解的前提下,对部分原始数据进行脱敏处理。
背景
生产环境 MySQL 硬件配置:32C/64G/2T ESSD
MySQL 版本:5.7.28
存储数据主要来源:主要是 Flink 实时计算的指标,少部分 Presto 准实时计算的指标,同时还有部分离线数仓模型也会每天同步一份至该 MySQL,用于加速客户端查询和提升并发查询能力。
发现问题
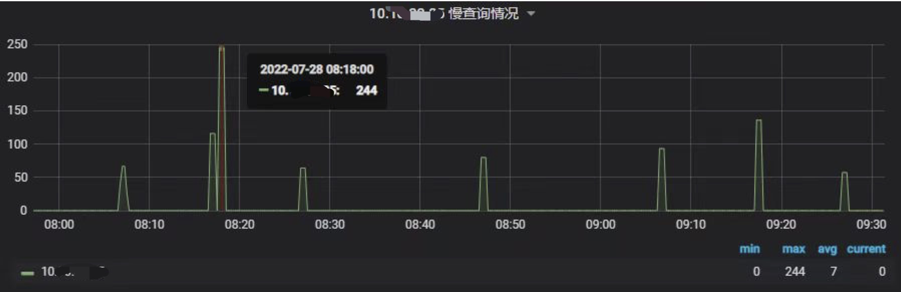
之前收到运维的反馈,生产环境上用于存放 Flink 实时计算指标的 MySQL 有告警——每分钟慢查询数超过告警阈值,需及时跟进。当时通过 MySQL 监控面板查看到部分关键指标如下:
慢查询数
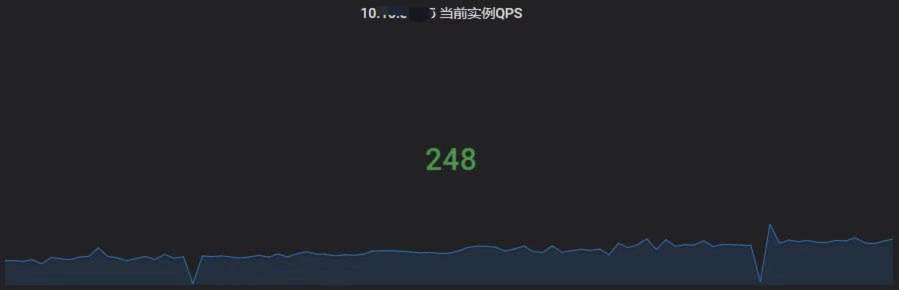
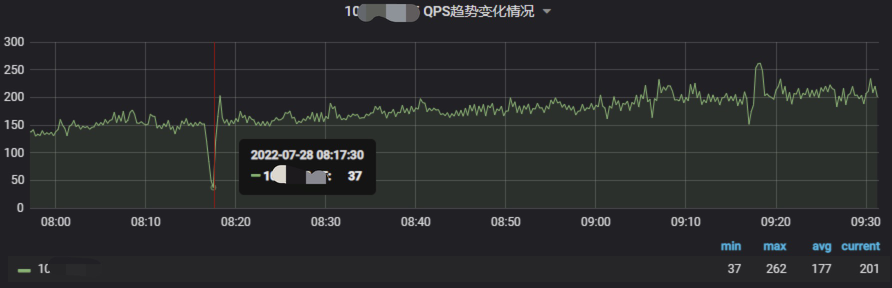
QPS
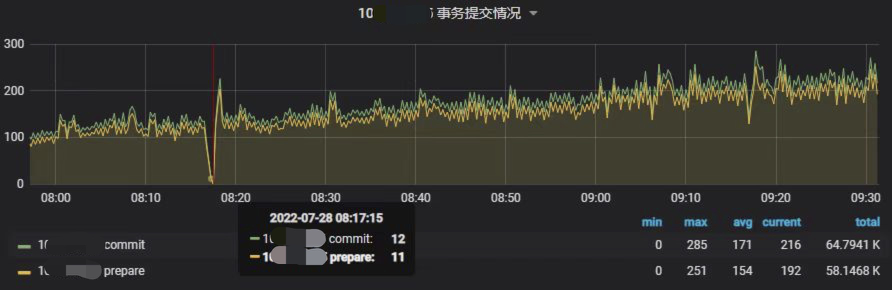
TPS
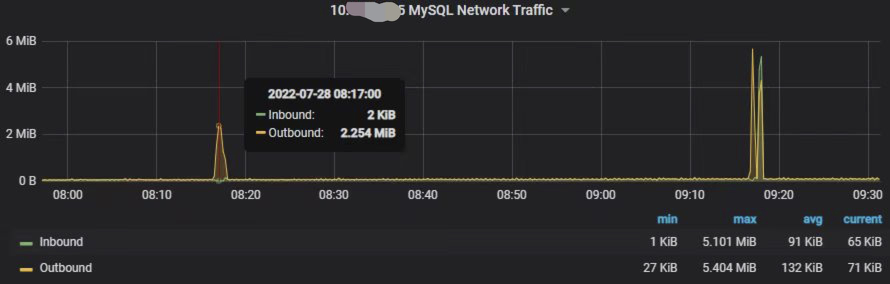
网络流量(流入、流出)
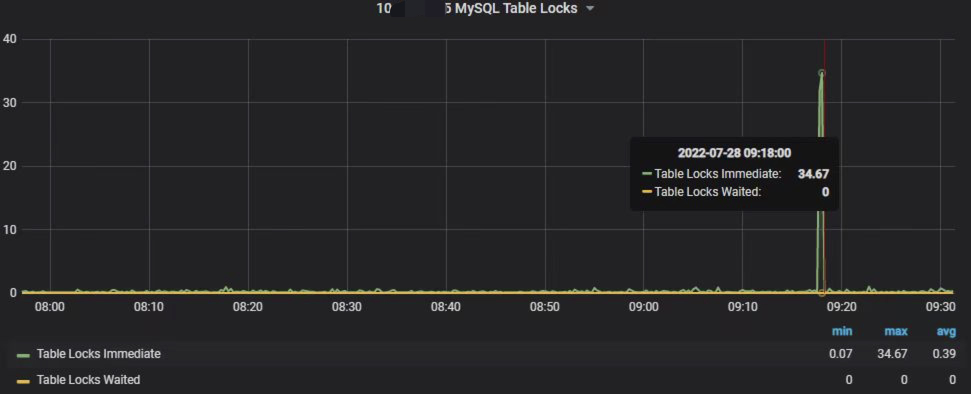
表锁
慢日志明细部分 SQL(当时只拉取一小部分的慢 SQL,以下这些语句是 Flink SQL 写入 MySQL 的)
1 | # Time: 2022-07-28T01:16:52.760142Z |
排查问题
从 MySQL 监控面板看到,慢查询的情况每天都在发生,而且呈现一定的规律:
- 一个是每天固定时段(凌晨 4 点半到 6 点之间,上午 9 点 15 到 20 分之间)会出现一次;
- 另一个是有周期性,大概每 20 分钟、每一小时都会出现一次。
- 每 20 分钟出现一次的情况:从每小时 06 分开始,每隔 20 分钟触发一次,如 08:06,08:26,08:46,09:06 等;
- 每一小时出现一次的情况:从每小时 15 分触发一次,如 08:15,09:15,10:15 等。
初步判断,慢查询问题应该是由离线数仓模型数据同步至 MySQL 和准实时系统 Presto 定时写数据到 MySQL 引起的。因为每天出现慢查询的固定时段与离线数仓计算的时段一致,而且也只有 Presto 是定时触发计算并写数据至 MySQL 的。
但为进一步排除是否由 Flink SQL 实时写 MySQL 导致的,这里也对部分慢 SQL 进行抽样验证——执行这些 SQL 是否真的很慢。如前文贴出的慢 SQL,涉及到两张表 tb_1 与 tb_2,查了表记录数,tb_1 为 7 万多,tb_2 不到 158 万。数据量都不算大,按理说这些 insert … on duplicate key update 不应该会出现慢查询情况。然后在非上述出现慢查询时段,手动执行一次该 SQL 进行验证,发现执行很快就完成,不存在执行时长十几秒的情况。
另外,如果慢查询是由 Flink 写 MySQL 导致的,那么 MySQL 的监控面板的慢查询数的趋势情况应该如下图所示,而不会出现某些时段慢查询数为 0 的情况。因为 Flink 写到 MySQL 的表,都是热点表,具有高频的写操作,高峰的时候可能会出现一秒内需要更新某一张表的某一行某一列多达 100 多次,最低峰的时候也会在十秒内更新一次。
解决问题
经过初步分析,基本上可以排除 Flink 实时写入导致慢查询,接下来开始重点关注离线数仓部分模型同步和 Presto 准实时写入的情况。
两种定位慢SQL方式
最简单粗暴的方式,是审查(Review)离线数仓数据清洗代码和 Presto 准实时调度代码,逐一排查与当前 MySQL 实例有关的代码,找出有问题的 SQL 并修复。这种方式虽然看起来直接简单,但没有针对性,效率并不高,一个是代码量较大,查找较费时,另一个是就算找到与当前 MySQL 实例有关的代码,这个代码也不一定是有问题的代码。
另一种方式,是拉取 MySQL 的 binlog 日志和慢查询日志进行定位。针对慢查询出现时段,定位该时段前、时段中,MySQL 在做什么操作。这种方式比较有针对性,效率也会高一些。本次定位慢 SQL 就采用该方式。
首先,从 MySQL 实例所在服务器下载慢日志文件(mysql1-slow.log)和慢查询出现时段的 binlog 日志文件(mysql-bin.012209)。
其次,在本地使用 mysqlbinlog 命令解析 binlog 日志文件,比如解析慢 SQL 出现时段的 binlog 日志(2022-07-28 08:10 ~ 08:30)至文本文件 binlog.txt 上:
1 | mysqlbinlog -v --base64-output=decode-rows --start-datetime="2022-07-28T08:10:00" --stop-datetime="2022-07-28T08:30:00" mysql-bin.012209 > binlog.txt |
使用 VS Code 打开 binlog.txt 文件,即可查看这个时段 MySQL 做了哪些操作。需要注意的是 binlog 日志并不记录查询(select 语句)相关的操作。
再次,使用 VS Code 打开慢日志文件(mysql1-slow.log),直接通过搜索日期的方式(如搜索 2022-07-28T00:10)定位到慢 SQL 出现时段都有哪些慢 SQL。如果慢日志文件太大的话,还可以使用 tail 命令,根据需要输出一万行,或十万行,或一百万行,或两百万行至另一个日志文件,再打开。如从慢日志文件输出十万行至 slow_072800.log 文件:
1 | tail -n 100000 mysql1-slow.log > slow_072800.log |
最后,结合这两个日志文件(优先是使用慢日志文件),找出慢 SQL 语句,并根据需要进行 SQL 优化等。
定位慢SQL示例 1
以本次慢查询为例,注意到 08:00 ~ 08:10 这个时段有大量的慢查询,我们可以先在慢日志文件中查找该时段都有哪些慢 SQL,主要关注两个重要指标:
- Rows_sent:慢查询返回记录;
- Rows_examined:慢查询扫描过的行数。
在该时段的慢 SQL 中,我们发现在 2022-07-28T00:06:32(此为UTC时间,北京时间需加 8 小时),有一条 SQL 的 Rows_examined 指标值为 6621900,即执行该 SQL 需要扫描 660 多万行数据:
1 | # Time: 2022-07-28T00:06:32.782972Z |
该 IP 地址 10.10.18.246,是 Presto 集群其中一个节点地址,可以断定这里的慢 SQL 来源于准实时调度。我们再以该 SQL 语句前面非参数部分内容(如 insert into db.tb_3)进行搜索,结果如下:
1 | # Time: 2022-07-28T00:26:30.317576Z |
可以看到,该 insert into … select 语句每 20 分钟执行一次,每次执行都扫描 600 多万行数据,每次执行该 SQL 都会阻塞其他 SQL 正常执行,导致大量的慢查询。
定位慢SQL示例 2
接下来排查 08:10 ~ 08:20 时段的慢查询问题。该时段对应的网络流量指标面板,可以看到流出的流量有明显的上升,服务器若无其他特殊操作,一般可以断定此时段是由于返回大量数据导致了流出流量上升。这时就没有必要去 binlog 日志文件查找 08:10 ~ 08:20 这个时段的 MySQL 操作,而是要去慢日志文件查找 08:10 ~ 08:20 时段的 select 语句。
通过慢日志,我们发现是以下这段查询 SQL 语句导到了慢查询:
1 | # Time: 2022-07-28T00:17:23.830780Z |
可以看到,执行该 SQL 语句需要扫描行数 400 多万,返回记录数 400 多万。一次查询就返回 400 多万数据,这是非常不合理的,也是流出流量异常上升的原因。
接着,再以该 SQL 语句前面非参数部分内容进行搜索,结果如下:
1 | # Time: 2022-07-28T01:16:52.759317Z |
可以看出,在每小时的 10 ~ 20 分这个时段的慢查询,是执行该 SQL 导致的,这期间服务器流出流量都会明显上升,而且 QPS/TPS 也出现明显的下降。
定位慢SQL示例 3
如果细心查看服务器的流量指标,会发现在 09:10 ~ 09:20 这个时段,服务器的流入流量有明显的上升(绿色的线)。如果此期间没有上传文件到服务器等特殊操作的话,说明此时段有大量的写操作。而且通过表锁指标看板,可以看到此时候的表锁次数也是明显的上升。基本上可以从这两个指标判断,此时段极有可能在执行类似 insert into … select 的 SQL 语句,插入大量数据,导致该操作从行锁升级成了表锁。
不过,在慢查询日志文件查找该时段的慢查询 SQL 时,并没有找到记录。但查找该时段的 binlog 日志,发现一个批量写入:以 BEGIN 开头,接着是 100 条 INSERT INTO 语句,然后才以 COMMIT 结尾。而且在 9 时 17 分 23~24 这两秒内,总共记录了 985 个批次。
1 | # at 934275431 |
根据此 SQL 的表名(db`.`xxxx_tmp),查了离线数仓和准实时的代码,发现在离线数仓中,有一个 shell 脚本调用 sqoop 命令将一个离线模型的数据(该模型记录数为 98467)导出到 MySQL。
sqoop 命令是以批的方式将 hive 的数据导出到 MySQL 的,所以这里只看到服务器的流入流量明显上升,但并没有产生慢 SQL。此时段的慢查询其实是示例 2 的 SQL 产生的,在 sqoop 执行批量写入的同时,准实时也恰好在该时段执行慢查询的 select 语句。
优化后
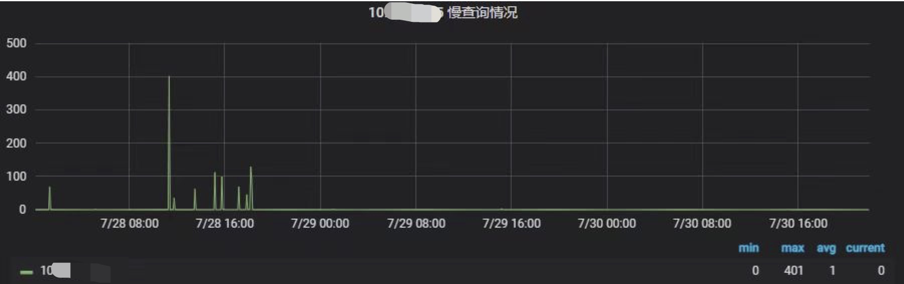
如下图所示,经过上述方式,找出慢 SQL 并优化后,后续没有再出现慢查询的情况。
小结
本文根据实际项目经验,主要记录了生产环境 MySQL 慢查询的排查过程。关于如何优化已发现的问题 SQL,本文没有涉及到。常见的优化手段一般是通过 explain 命令来查看 SQL 执行计划,并以此调整 SQL 的写法。
多数据情况下,定位慢 SQL 都是通过慢查询日志进行定位的。借助服务器的部分关键指标,可以有效提高排查效率。
例如,我们知道导致慢 SQL 最常见的原因是大事务。而大事务通常是没有限定好 SQL 扫描表的行数,导致每次执行,都要扫描几十万行,甚至几百万行数据。如 SQL 语句是往目标表写入几百万行数据,或者是从目标表查询返回几十万行数据等。执行这样的 SQL 语句,有一个特征是 MySQL 实例所在服务器的网络流量会有明显的变化:
- 写入大量数据,服务器的流入流量会明显上升;
- 查询返回大量数据,服务器的流出流量也会有明显的上升。
我们可以根据该特征来判断某个时段的慢查询是由于写入还是查询导致的。并根据出现慢查询的时段,快速定位慢查询日志文件中的慢 SQL。
需要注意的是,慢查询日志文件中记录的慢 SQL,不一定都是有问题的 SQL,因为有可能是某条正在执行慢 SQL 语句,阻塞了其他 SQL 语句正常执行。这种情况一般可以通过慢查询日志中的 Rows_sent(慢查询返回记录)和 Rows_examined(慢查询扫描过的行数)两个指标快速排查。
(END)

