
Python 编程指南 | 使用 with 关键字
Python with 语句的作用是在语句块执行完毕后,自动调用 with 后面表达式的 __exit__ 方法。这允许我们不必显式地调用 close 方法,就可以确保资源总会被释放。with 语句可以使代码更清晰、更具可读性,简化了文件流、数据库连接等公共资源的管理。 使用 with 示例一个最常见的例子是打开文件,使用 with 关键字,我们可以这么写: 12with open('file.txt') as f: read_data = f.read() 使用 with 关键字,我们不必显式调用 f.close() 来关闭文件。with 语句会在读取文件后自动关闭该文件。 如果我们不使用 with 关键字,为了避免在读取文件的过程中出现异常,使文件不能被正常关闭,导致文件资源一直被该程序占用而无法被释放,我们需要使用 try…except…finally 编码范式,具体代码如下: 1234567try: f = open('file.txt') read_data = f.read()except Exception as...
Ubuntu 20.04 systemctl 错误:System has not been booted with systemd as init system (PID 1). Can't operate.
在 Ubuntu 20.04 系统中,使用 systemctl 命令启动 logstash,出现以下错误: 123$ systemctl start logstashSystem has not been booted with systemd as init system (PID 1). Can't operate.Failed to connect to bus: Host is down 这是因为 systemctl 不是 Ubuntu 系统自带的命令,可以通过 apt 命令进行安装: 1sudo apt install systemctl 安装过程中,会提示你输入 Yes, do as I say! 以继续安装。 (END)
如何查看通过 systemctl 命令启动的服务的日志
systemctl 是 Linux 系统服务管理工具,它可以用来启动、停止、重启、启用或禁用系统服务。当我们启动一个服务时,systemctl 会记录服务的启动日志,我们可以通过查看这些日志来排查服务启动时的问题。 查看 systemctl 服务日志的步骤如下: 找到服务的完整名称。系统服务的名称通常以 .service 结尾,例如 httpd.service、mysql.service 等。 使用 journalctl 命令查看服务的日志。命令格式为: 1journalctl -u <服务名称> 将 <服务名称> 替换为服务的完整名称。例如,要查看 httpd 服务的日志,运行: 1journalctl -u httpd.service journalctl 会输出服务的启动日志、运行日志和停止日志。 (END)
Endpoint 是什么?
Endpoint 翻译成中文是端点、终点或终结点的意思。在通信领域,Endpoint 是指连接到网络系统的物理设备,例如移动设备、台式计算机、虚拟机、嵌入式设备和服务器。 Endpoint 定义广义上,Endpoint 一般是指连接到计算机网络并与之交换信息的物理设备。Endpoint 的一些例子是手机移动设备、台式计算机、虚拟机、嵌入式设备和服务器。物联网设备——如摄像头、照明、冰箱、安全系统、智能扬声器和恒温器——也是 Endpoint。 但在计算机网络应用领域上,Endpoint 是指网络上的一个接口或地址,通过它可以访问网络服务或应用程序。它通常向客户端提供一组可调用的接口或API。 举些例子: REST API 的 URL 就是 Endpoint,客户端可以通过这个 Endpoint 访问 API 提供的服务。 WebSocket 的 URL 就是 Endpoint,客户端可以通过这个 Endpoint 与服务器建立双向通信。 SMTP 邮件服务器的域名就是 email 发送的 Endpoint。 数据库服务器监听的 IP 和端口就是数据库的 Endpoint。 总...
Filebeat 配置 Http Endpoint
Filebeat 可以通过 HTTP 终点来暴露内部的指标。这些指标对于监控 Beat 的内部状态很有用。但出于安全原因,该功能默认是禁用的。要开启该功能,需要在 filebeat.yml 文件中添加以下配置项: 12http: enabled: true 开启了该功能后,在浏览器访问地址 http://localhost:5066/stats 即可查看各项统计指标。要美化 JSON 输出数据格式,可以在该地址后面加上 ?pretty ,即:http://localhost:5066/stats?pretty 需要注意的是,这个功能目前还是实验性的。 HTTP 终点配置说明 配置 可选/必填 默认 说明 http.enabled (可选) false 启用 HTTP 终点。 http.host (可选) localhost 绑定到这个主机名、IP 地址、unix 套接字(unix:///var/run/filebeat.sock)或 Windows 命名的管道(npipe:///filebeat)。建议只使用 localhost。默认为 localhost...
Python 编程指南 | 在 JSON 序列化的过程中,如何保证对象属性中的 Unicode 或非 ASCII 字符串能够原样输出
默认情况下,当对象属性包括 Unicode 或非 ASCII 字符串时,使用 Python 的 JSON 模块进行 JSON 序列化,会将这些字符串转换为 \u 转义序列。这个转义序列由一个反斜杠(\)和一个 u 以及四个十六进制数字组成,代表该字符的 Unicode 码位。 例如,下面示例代码中,将字典对象 my_dict 序列化成 JSON 字符串后,zh 字段的值变为 \u4eba\u751f\u82e6\u77ed\uff0c\u6211\u7528Python\u3002。 123456789101112131415161718192021#!/usr/bin/env python3# -*- coding: utf-8 -*-import json# 定义一个字典对象my_dict = { "zh": "人生苦短,我用Python。", "en": "Life is short, use Python."}# 使用 json.dumps() 方法将字典对象序...
Python AES 解密出错:TypeError: 'iv' is an invalid keyword argument for this function
使用 AES 算法对字符串进行解密,Python 代码片段如下: 12345678910111213141516import base64from Crypto.Cipher import AESdef aes_decrypt(encrypted_str): """使用AES加密算法对encrypted_str进行解密""" bt = encrypted_str.encode() base64_code = base64.b64decode(bt) aes = AES.new(key=encoding_aes_key.encode(), mode=AES.MODE_CBC, iv=iv.encode()) decrypted = aes.decrypt(base64_code) # 移除padding并解码 padding_length = decrypted[-1] removed_padding = decrypted[:-padding_length] # 返回...
使用 Logstash 的 geoip 插件解析 IP 地址的归属地
本文演示如何使用 geoip 插件解析 IP 地址的归属地。 1、启动 Logstash 新建配置文件 geoip-demo.conf,并输入以下内容: 1234567891011121314input { stdin { codec => 'json' }} filter { geoip { source => '[ip]' target => source }} output{ stdout{} } 使用 -f 参数指定到配置文件 geoip-demo.conf 启动 Logstash: 1/usr/share/logstash/bin/logstash -f /mnt/d/src/yaybyc/geoip-demo.conf 如果只是为了测试,也可以不创建配置文件,直接使用 -e 参数指定配置的方式启动: 1/...
Git 标签管理——代码切换到指定的 Tag 上
本文以 Github 上的 logstash-filter-geoip 项目为例,演示如何将代码切换到指定的 Tag 上。 使用 git clone 从 Github 上将 logstash-filter-geoip 代码克隆至本地: 1git clone https://github.com/logstash-plugins/logstash-filter-geoip.git 进入代码目录: 1cd logstash-filter-geoip 使用 git tag 查看所有的 Tag: 1git tag 结果如下(注意,显示的标签列表不是按标签创建时间顺序来排序的,而是按字母排序的): 123456789101112131415161718v0.1.0v0.1.1v0.1.10v0.1.2......v7.2.1v7.2.10v7.2.11v7.2.12v7.2.13v7.2.2v7.2.3v7.2.4v7.2.5v7.2.6v7.2.7v7.2.8v7.2.9 使用 git checkout 切换至标签 v7.2.13: 1git checkout v7.2.13 结果如下...
Linux 常用命令 | pwgen 详解
pwgen 是一个生成密码的小工具,可以通过参数生成满足各种条件的密码,如生成的密码至少要包含一个特殊字符,或生成的密码不要包含数字,或生成长度为 16 的密码等。 安装在 Ubuntu 操作系统,可以直接通过 apt-get 方式安装: 1apt-get install pwgen 在 CentOS 操作系统,需要先安装 epel-release 软件包后才能使用 yum 方式安装 pwgen。 安装 epel-release: 1yum install -y epel-release 安装 pwgen: 1yum install -y pwgen 用法1pwgen [ 选项 ] [ 密码长度 ] [ 密码数量 ] 例如,生成 4 个长度为 8 的密码: 1pwgen 8 4 结果如下: 12$ pwgen 8 4Hah8eeth ies6Yuxu iemoo1Ko aeB7shu4 pwgen 支持的选项 选项 说明 -c 或 —capitalize 在密码中至少包含一个大写字母 -A 或 —no-capitalize 不在密码中包含大写字母 -n 或 ...
【持续更新】iPhone 设备型号对应型号名称、手机型号对应屏幕尺寸及分辨率列表
当前已更新至 iPhone 14 Pro Max。 iPhone 设备型号对应手机型号名称 设备型号(固件标识符) 手机型号名称 iPhone1,1 iPhone iPhone1,2 iPhone 3G iPhone2,1 iPhone 3Gs iPhone3,1 iPhone 4 iPhone3,2 iPhone 4 iPhone3,3 iPhone 4 iPhone4,1 iPhone 4s iPhone5,1 iPhone 5 iPhone5,2 iPhone 5 iPhone5,3 iPhone 5c iPhone5,4 iPhone 5c iPhone6,1 iPhone 5s iPhone6,2 iPhone 5s iPhone7,2 iPhone 6 iPhone7,1 iPhone 6 Plus iPhone8,1 iPhone 6s iPhone8,2 iPhone 6s Plus iPhone8,4 iPhone SE (第一代) iPhone9,1 iPhone 7 i...
解决 Logstash 在出现解析异常时 logstash-plain.log 日志文件没有记录原始数据问题
我在使用 Logstah 处理数据时,在 logstash-plain.log 文件中发现了以下的错误信息: 1234[2023-03-31T00:10:28,949][ERROR][logstash.filters.ruby ][main][d6838068510d1ed4e2d1025930d8680ca59bdef970aaa32f4e2d8d28a09ee6d3] Ruby exception occurred: unexpected token at '' {:class=>"JSON::ParserError", :backtrace=>["json/ext/Parser.java:238:in `parse'", "/usr/share/logstash/vendor/bundle/jruby/2.6.0/gems/json-2.6.3-java/lib/json/common.rb:216:in `parse'", "(ruby...
Apache Kafka 如何通过全局和针对特定 Topic 设置消息的保留时长
在使用 Kafka 作为消息队列缓冲数据时,在某些业务使用场景中,我们可能需要根据实际情况调整消息在 Kafka 的保留时长。例如,对于用户行为埋点日志的数据,因为数据量较大,而且也没有必要保留 7 天(Kafka 默认消息保留时长),为减少 Kafka 集群的压力,此时就可以通过针对保存该类消息的 Topic 设置消息保留时长为 3 天。本文介绍如何通过全局和针对特定 Topic 设置 Kafka 的消息保留时长。 前提条件本文的演示示例基于 CentOS 7 操作系统,使用的是 Apache Kafka,版本为 2.2.1,Scala 版本为 2.11,安装目录位于 /opt/kafka。 Kafka 全局消息保留时长设置首先,进入 Kafka 的配置文件目录,通常位于 Kafka 安装目录下的 config 目录下: 1cd /opt/kafka/config 打开 Kafka 服务端的配置文件 server.properties: 1vim server.properties 找到配置项 log.retention.hours,可以看到该配置项默认为 168 小时,即 7...
Logstash如何将JSON第二层级的数据解析到第一层级
此示例演示如何使用 Logstash 将 JSON 第二层级的数据解析到第一层级(JSON 根)。 例如,原始 JSON 数据格式如下: 123456789101112131415161718192021222324252627{ "distinct_id":"u24a21a5e262debf", "time":"1679912055733", "time_offset":"0", "type":"track", "event":"ExposureView", "properties":{ "$app_version":"8.3", "$wifi":true, "$ip":"39...
Apache Flink 1.17 发版公告
本文翻译自 Apache Flink 社区博文——《Announcing the Release of Apache Flink 1.17》 Apache Flink PMC(项目管理委员会)很高兴地宣布发布 Apache Flink 1.17.0 版。Apache Flink 是领先的流处理标准,统一的流和批数据处理概念正被越来越多的公司成功采用。得益于我们优秀的社区和贡献者,Apache Flink 作为一项技术在不断发展壮大,并且仍然是 Apache 软件基金会中最活跃的项目之一。Flink 1.17 版本有 172 位贡献者热情参与,完成了 7 个 FLIP 和 600 多个问题,为社区带来了许多令人兴奋的新功能和改进。 迈向流式仓库为了在流式仓库领域实现更高的效率,Flink 1.17 在批处理性能和流处理语义方面进行了大量改进。这些改进标志着朝创建更高效、更精简的数据仓库迈出的重要一步,使其能够实时处理大量数据。 对于批处理而言,此版本包含了多项新功能和改进: 流式仓库 API:FLIP-282 在 Flink SQL 中引入了新的删除和更新 API,该 API ...

Java 如何将 Iterator 转换为 List
在本文中,我们将学习在 Java 中如何把一个 Iterator 转换成一个 List。 为便于代码测试,我们在所有的示例代码中使用一个元素为字符串类型的 Iterator : 12Iterator<String> iterator = Arrays.asList("MONDAY", "TUESDAY", "WEDNESDAY", "THURSDAY", "FRIDAY", "SATURDAY", "SUNDAY").iterator(); 方法一:使用 While 循环一个容易想到的方法是使用 while 循环将 Iterator 转换为 List。具体代码如下: 12345678910111213141516171819202122232425262728// 此代码示例演示 while 循环方法的使用package com.johnson.java.fundamentals.collection...
【Linux常用命令】head——把一个文件的前n行拷贝到另一个文件上
在日常开发工作中偶尔需要查看文件前 n 行的内容,如果文件的大小为几个 GB 时,直接打开文件会很慢,这个时候我们可以通过复制文件的前 n 行到另一个文件上进行查看。 在 Linux 环境中可以使用 head 命令来复制一个文件的前 n 行到另一个文件上。如以下命令表示复制文件 nginx_app_log_20230320.log 中前 10 万行内容到 /tmp 目录下的 app0320_top10w.log 文件中: 1head -n 100000 nginx_app_log_20230320.log > /tmp/app0320_top10w.log (END)
Linux 常用命令 | head 详解
Linux 命令行工具提供了足够丰富的命令用于管理服务器上的文件和目录。其中最常用的命令之一是 head,它允许我们只查看文件的前几行内容,这在查看超大文件(文件大小为几个 GB 以上)时尤其有用。在这篇博文中,我们将详细讨论该命令的使用说明、注意事项、技巧窍门等,以充分利用该命令。 使用说明head 命令用于显示一个文件的前几行。要使用该命令,只需输入 head 和你想查看的文件名即可。例如,要查看一个名为 example.log 的文件的前10行,你可以输入以下命令: 1head -n 10 example.log 其中,-n 选项用于指定要查看的行数。如果不指定数字,它将默认为 10 行。还可以使用 - 号来表示除了文件最后多少行外输出所有行内容。例如,要查看文件的所有行,但不包括最后的 11 行,可以输入以下命令: 1head -n -11 example.log 注意事项在使用 head 命令时,有两个地方需要注意: 首先,注意不要使用 > 操作符意外覆盖原来的文件。例如,执行以下命令会导致 example.log 文件被其前 10 行的内容覆盖,相当于 exam...
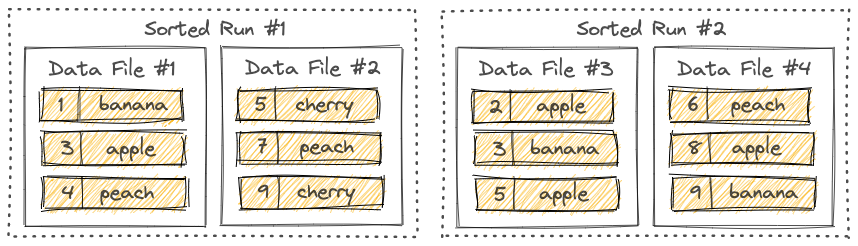
Flink Table Store文件存储结构——LSM树
本文简要介绍了 Flink Table Store 底层文件存储的数据结构——LSM 树的相关概念。 LSM 树,亦称日志结构合并树,英文为 log-structured merge-tree。 Sorted Runs如下图所示,LSM 树将文件组织成若干个 Sorted Run,一个 Sorted Run 由一个或多个数据文件组成,每个数据文件只会隶属一个 Sorted Run。数据文件中的记录按主键排序,在一个 Sorted Run 中,数据文件的主键范围不会有重叠的情况。但在不同的 Sorted Run 中主键范围有可能会重叠,甚至是包含相同的主键。 当查询 LSM 树时,必须先合并所有的 Sorted Run,根据用户指定的合并引擎和每条记录的时间戳合并具有相同主键的所有记录。而新的记录在写到 LSM 树之前会先缓存在内存中,当内存缓冲区满时,内存中的所有记录会先进行排序,然后再刷到磁盘上,此时就创建了一个新的 Sorted Run。 Compaction随着越来越多的记录写入 LSM 树,Sorted Run 的数量也会越来越多。因为查询 LSM 树需要先合并所有...
Filebeat工作原理
本文主要介绍 Filebeat 的两个关键组件以及它们如何共同协作完成数据采集和转发工作。理解并熟练掌握这些组件的工作原理将对后面深入学习 Filebeat 的各种功能和特性,尤其是为特定使用场景配置 Filebeat 时大有裨益。 Filebeat 由两个关键组件构成:输入(Input)和采集器(Harvester,[ˈhɑːrvɪstər])。这些组件共同协作,跟踪日志文件,并将事件数据发送到指定的输出上。 采集器采集器逐行读取文件内容并将其转换为事件,然后发送到指定的输出上。一个采集器只会跟踪一个日志文件。需要注意的是,采集器还负责文件的打开与关闭——采集文件之前需要先打开文件,采集结束之后需要关闭文件。在采集的过程中,文件会一直保持打开的状态。也就是说,如果在采集期间移除或重命名文件,采集器仍会继续读取该文件,这会导致磁盘空间不被释放,除非关闭采集器。 默认情况下,Filebeat 保持文件为打开状态的时长取决于配置项 close_inactive 设置的时长。如果一个文件在设定的时间内没有新增数据,即 Filebeat 在设定的时间内没有从该文件中采集到数据,那么 F...

