
深入解析Gson:一个强大的Java JSON库
引言在现代的软件开发中,处理 JSON 数据是非常常见的任务。而为了简化 JSON 数据的解析和生成过程,我们可以借助一个强大而灵活的 Java 库——Gson。作为一个非常流行的开源 Java 库,它的主要用途是将 Java 对象序列化为 JSON 字符串,或者将 JSON 字符串反序列化为 Java 对象。它提供了简单易用的 API,使得处理 JSON 数据变得轻而易举。本篇博文将详细介绍 Gson 库的特性和使用方法,并通过示例代码展示其在实际场景中的应用。 Gson 经历了多个版本的迭代,目前已经成熟而稳定,处于维护模式。这意味着它会继续修复现有的错误,但可能不会添加大型的新功能。 Gson的特性 简单易用:Gson 提供了简洁的 API,使得将 Java 对象序列化为 JSON 或将 JSON 反序列化为 Java 对象变得非常简单。 高度灵活:Gson 支持自定义序列化和反序列化的规则,可以满足各种复杂的数据结构和业务需求(具有深度继承层次结构并广泛使用泛型类型)。 配置灵活:通过设置不同的配置选项,如日期格式、字段排除策略等,可以灵活地控制 Gson 的行为。 ...
探索流式应用的性能指标:延迟和吞吐量解析
批处理应用和流式应用在性能需求上有所区别。对于批处理应用而言,我们通常关心作业的总执行时间,即从处理引擎读取输入、执行计算、写回结果所需的时间。但在数据流处理中,由于流式应用会持续执行且输入可能是无限的,所以没有总执行时间的概念。相反,流式应用需要尽可能快地计算结果,并能处理高速的事件接入。因此,我们用延迟和吞吐来表示这两方面的性能需求。 延迟延迟是指处理一个事件所需的时间,从接收事件到在输出中观察到事件处理效果的时间间隔。为了更直观地理解延迟,我们可以以去咖啡店喝咖啡为例。当你进门时,可能已经有其他顾客在里面了,需要排队等候。收银员收到你的付款后,将订单交给咖啡师准备饮品。饮品制作完成后,咖啡师会叫你的名字,你才能从吧台取走咖啡。在这个过程中,你在店内买咖啡的时间就是服务延迟,即从进门到喝到第一口咖啡的时间。 在流处理中,我们用时间片(如毫秒)来测量延迟。根据应用的不同,我们可能关注平均延迟、最大延迟或特定百分位数的延迟。例如,平均延迟为 10 毫秒表示平均每条数据在 10 毫秒内处理完毕,而第 95 百分位延迟在 10 毫秒内处理完毕意味着 95% 的事件都在 10 毫秒内处...
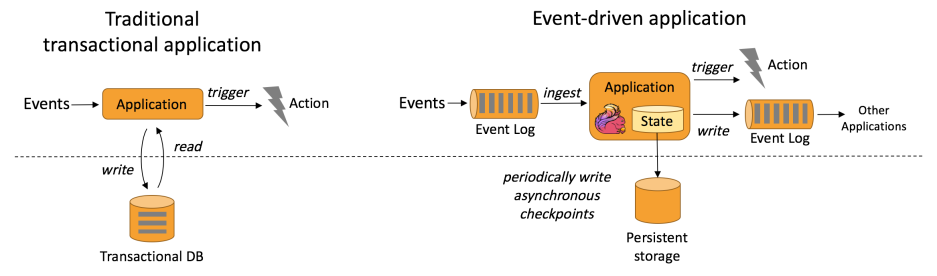
探究Apache Flink支持的三种流处理场景
Apache Flink 是一个集众多具有竞争力的特性于一身的流处理引擎,是开发和运行多种不同类型应用程序的绝佳选择。Flink 提供了流处理和批处理支持、复杂的状态管理、事件时间处理语义以及状态的精确一次一致性保证等功能。此外,Flink 可以在多种资源管理框架上部署,比如 YARN 和 Kubernetes,也可以作为独立集群部署在裸机硬件上。Flink 的高可用配置确保了系统没有单点故障。实际上,Flink 能够扩展到数千个内核和 TB 级的应用状态,提供高吞吐量和低延迟,并为世界上一些要求最苛刻的流处理应用提供支持。 本文将介绍 Flink 支持的三类常见的有状态的流处理应用,分别为事件驱动型应用、数据管道应用和数据分析应用。 注:这里为了突出有状态的流处理的用途之多,将不同应用的类别区分地很明显,而事实上大多数真实应用都会同时具有多种类别的特性。 事件驱动型应用第一种应用类型是事件驱动型应用。事件驱动型应用程序是有状态的应用程序,它从一个或多个事件流中摄取事件,并通过触发计算、状态更新或执行外部操作来响应这些事件。事件驱动型应用本质上是传统应用程序的演变。传统的应用...
不要浪费你的中年危机
我上个月刚满40岁,花了三周时间阅读《堂吉诃德》,因此中年危机一直在我的脑海中挥之不去。 “千万不要浪费你的中年危机。” 这是我在收听播客采访《威廉・布莱克与世界》(William Blake vs. The World)的作者约翰・希格斯(John Higgs)时听到的建议。(2022年我最喜欢的读物之一)。 希格斯说,他钦佩的艺术家都是像大卫・林奇(David Lynch)这样的人,“你不会觉得他们在这个世界上有什么明显的位置,但他们就是不顾一切地做自己的事情,于是一个位置就在他们周围建立起来了”。 他继续说道: “生态学中有一个概念叫‘生态位创造’(niche creation)。它的意思是:一个物种来到一个地方,不是因为‘哦,这里有充足的食物,我可以在这里生存得很好’。而是这个物种本能地做它该做的事,通过和环境的互动,它创造了一个有利于自己生存的环境。 当我决定尝试成为一名全职作家时——尽管考虑到写作这个行业的盈利模式的荒谬性——我有一种信仰,那就是只要我去做了,那些读我的书的人就会开始出现。慢慢地,随着时间的推移,我会逐渐建立起一些读者群体,他们会说:‘哦,这个人很有意...
深入探索Gson的泛型序列化和反序列化能力
在 Java 开发领域,序列化和反序列化是常见的操作,用于将对象转换为字节流以便在网络传输或存储中使用。Gson 是 Google 提供的一个优秀的 Json 序列化和反序列化库,提供了强大的功能和灵活性。本文将重点介绍 Gson 在处理泛型类型时的序列化和反序列化能力。 Gson 的泛型支持Gson 通过使用 TypeToken 类来支持泛型。TypeToken 提供了一种表示泛型类型的方式。通过创建 TypeToken 的子类,我们可以捕获泛型的具体类型信息,从而实现更精确的序列化和反序列化操作。 泛型对象的序列化在进行泛型序列化时,我们需要构建一个 TypeToken 对象来表示特定的泛型类型。例如,对于 List<String> 类型,可以使用如下方式进行序列化: 1234Gson gson = new Gson();Type listType = new TypeToken<List<String>>(){}.getType();List<String> list = new ArrayList<...

培养你对数学的直觉
我们对一个新概念的首次接触,往往会形成我们心中对其的第一印象或直觉认知。而这一直觉,也会反过来影响我们在多大程度上喜欢或者认同这个概念。 以“猫”为例,我们可以给出不同角度的定义: 山顶洞人视角:一种毛茸茸的动物,具有尖爪、锋利牙齿、灵活尾巴与四条腿,心情愉悦时会发出咕噜声,生气时会发出威胁的嘶嘶声…… 进化论视角:作为猫科动物的一员,猫是哺乳类动物的一个物种,拥有某些共同遗传特征…… 现代基因视角:猫不过是拥有以下DNA序列的动物:ACATACATACATACAT…… (插图来源:Common Craft) 毫无疑问,现代基因视角提供了最准确的定义。但是,这就足以成为解释“猫”的最佳起点吗?如果要让一个孩子理解“猫”的含义,我们会只给出这种定义吗?它能让我们深入理解猫的本质吗?答案似乎是否定的。现代定义固然准确实用,但应建立在对“猫”有一定认识的基础上,而非概念学习的起点。 不幸的是,数学理解往往也遵循类似的模式。我们被教授现代严谨的定义,而不是产生这些定义的逻辑过程。我们只掌握了晦涩难懂的公式,而对其背后的数学思想知之甚少。 我们不妨换个角度思考。想象一个圆圈:中心是你正...
使用Gson对嵌套类进行序列化和反序列化
本文将重点介绍如何使用 Gson 序列化嵌套类,包括内部类。 什么是嵌套类?在 Java 中,嵌套类是指在一个类的内部定义的另一个类。嵌套类可以分为两种类型:静态嵌套类(也称为静态内部类)和非静态嵌套类(也称为成员内部类)。静态嵌套类与外部类之间没有直接的引用关系,而非静态嵌套类则与外部类实例相关联。 Gson序列化嵌套类的基本用法Gson 可以很容易地序列化和反序列化静态嵌套类。 要使用 Gson 序列化嵌套类,我们首先需要确保 Gson 库已添加到项目中。可以通过 Maven、Gradle 或手动下载 jar 包的方式导入 Gson 库。 例如,如果使用 Maven,在 pom.xml 文件中添加以下依赖项: 123456<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version> <scope>comp...
使用Gson进行数组、集合和映射的序列化与反序列化
在开发过程中,我们经常需要将数据进行序列化和反序列化。序列化是将对象转换为可传输或可存储的格式,而反序列化则是将序列化后的数据重新还原成对象。针对数组、集合和映射这些常见的数据结构,Google 提供了一个强大而灵活的 Java 库——Gson。本文将介绍如何使用 Gson 进行数组、集合和映射的序列化与反序列化。 引入Gson库首先,我们需要在项目中引入 Gson 库。可以通过 Maven 或 Gradle 配置文件添加以下依赖项: Maven 123456789<dependencies> <!-- Gson: Java to JSON conversion --> <dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version> <scope>compi...
深入了解Gson:Java对象的序列化和反序列化
本文将介绍一些使用 Gson 库进行对象序列化时需要注意的细节,帮助开发人员更好地理解和应用该库。 引入Gson库首先,需要确保项目中已经正确引入了 Gson 库。可以通过 Maven、Gradle 或手动下载 jar 包的方式导入 Gson 库。 例如,如果使用 Maven,在 pom.xml 文件中添加以下依赖项: 123456<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version> <scope>compile</scope></dependency> 创建Gson对象在使用 Gson 库之前,需要创建一个 Gson 对象。可以直接使用默认的 Gson 构造函数创建一个 Gson 对象,也可以根据需要配置一些参数。 例如,如果希望将 JSON 字符串格式化输出,可以使用 Gs...

Hive表备份
在数据处理和分析的过程中,随着业务的发展和变化,我们可能需要对已有的 Hive 表进行调整、清理或修改表结构。为了确保操作的安全性,我们可以在进行这些操作之前先对 Hive 表进行备份。这样一来,即使在操作过程中发生了任何问题,我们也可以通过回退到备份数据来恢复之前的状态。 此外,在测试和开发环境中,我们经常需要使用真实的生产数据或者对数据进行一些实验性的操作。为了确保测试和开发工作不会对真实的生产数据造成影响,我们可以从 Hive 表中复制一份数据出来,创建一个安全的数据副本供测试和开发使用。从而可以在不影响真实生产数据的前提下进行各种实验和调试工作。 那么,如何快速备份或复制 Hive 表呢?本文将向大家介绍两种简单易行的复制 Hive 表的方法,以确保我们的数据始终处于安全可靠的状态。 方法一:使用 create table ... as ...直接使用 create table ... as ... 复制表数据、表字段。语法如下:123create table if not exists 表名as select * from 要备份的表名 使用该方法虽然可以复制表的数据与...
LeetCode1:两数之和
难度:容易 题目链接:https://leetcode-cn.com/problems/two-sum/ 数据结构:数组,哈希表 题目描述给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺序返回答案。 示例 1: 输入:nums = [2,7,11,15], target = 9输出:[0,1]解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1]。 示例 2: 输入:nums = [3,2,4], target = 6输出:[1,2] 示例 3: 输入:nums = [3,3], target = 6输出:[0,1] 约束: 2 <= nums.length <= 104 10^9 <= nums[i] <= 10^9 10^9 <= target <= 10^9 只会存在一个有效答案 进阶:你可以想出一个时间复杂度小于 O(...
使用Gson库在Java中实现下划线与驼峰格式的转换
当我们处理 JSON 数据时,经常会遇到下划线格式与驼峰格式之间的转换。为了简化这一过程,我们可以使用 Gson 库进行数据的相互转换。在本篇博文中,我们将介绍如何使用 Gson 实现下划线与驼峰格式的转换。 Gson 是一个流行的 Java 库,用于将 JSON 数据与 Java 对象进行相互转换。它提供了灵活的配置选项,以满足各种需求,其中包括下划线与驼峰格式的转换。 添加Maven依赖首先,在 pom.xml 文件中配置 gson 依赖项: 12345<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version></dependency> gson 版本根据实际情况进行选择,建议使用最新版本(见 Maven Central )。 本文使用的是 2.10.1 版本(当前最新版本)。 将下划线格式的JSON字符串转...

Java使用Gson库格式化输出JSON字符串
在本文中,我们将深入探讨如何在 Java 中格式化 JSON 数据以增强其可读性。 在处理大量的 JSON 对象时,理解和调试它们可能是一项艰巨的任务。因此,采用格式化输出 JSON 对象的方法变得至关重要。 为此,我们可以使用 Gson 库的功能。Gson 提供了便捷的方法来生成格式良好的 JSON 输出。 首先,添加 Gson Maven 依赖项: 12345<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version></dependency> gson 版本根据实际情况进行选择,建议使用最新版本(见 Maven Central )。 本文使用的是 2.10.1 版本(当前最新版本)。 为了格式化打印 JSON 字符串,我们将使用 GsonBuilder 的 setPrettyPrinting() 方法: 12...
HiveSQL内置函数——concat_ws
定义与使用函数 concat_ws() 将两个或多个表达式与分隔符添加在一起。 注:另请参阅 CONCAT() 函数。 语法11concat_ws(string SEP, string A, string B...) 参数值 参数 说明 SEP 必填。在每个表达式之间添加的分隔符。如果分隔符为 NULL,则返回 NULL。 A,B,等 必填。要连接的字符串。值为 NULL 的字符串将被跳过。 示例 1234select concat_ws('-', 'Johnson', 'Lin'), concat_ws('-', NULL, 'Lin'), concat_ws(NULL, 'Johnson', 'Lin') 以上代码的查询结果为 12345+-----------+---+----+|_c0 |_c1|_c2 |+-----------+---+----+|Johnson-Lin|Lin|NU...
MySQL表添加字段时报错:1062 - Duplicate entry 'xxxx' for key 'idx_unique'
当我们向一个已存在的 MySQL 表中添加新字段时,有时会遇到 1062 错误: 11062 - Duplicate entry 'xxxx' for key 'idx_unique' 这个报错的含义是在一个唯一索引(unique index)下有重复的值。 MySQL 官方文档《InnoDB 在线 DDL 限制》有一段关于该错误的说明,原文内容如下: When running an online DDL operation, the thread that runs the [ALTER TABLE](https://dev.mysql.com/doc/refman/5.7/en/alter-table.html) statement applies an online log of DML operations that were run concurrently on the same table from other connection threads. When the DML operations are applied, ...

Apache Paimon | 概述
Apache Paimon(孵化中)是一个流式数据湖平台,支持高速数据摄取、变化数据跟踪和高效的实时分析。 架构 如上面的架构图所示: 读/写:Paimon 支持以多种方式读/写数据和执行 OLAP 查询。 对于读取,它支持消费 历史快照(批处理模式)的数据, 从最新偏移量(流处理模式)读取数据,或者 以混合方式读取增量快照。 对于写入,它支持从数据库的变化日志(CDC)中进行流式同步,或从离线数据中批量插入/覆盖。 生态系统:除了 Apache Flink 之外,Paimon 还支持其他计算引擎的读取,如 Apache Hive、Apache Spark 和 Trino。 内部原理:Paimon 在文件系统/对象存储中存储列式文件,并使用 LSM 树结构来支持大量数据更新和高性能查询。 统一存储对于像 Apache Flink 这样的流引擎,通常有三种类型的连接器: 消息队列,如 Apache Kafka,用于管道的源头和中间阶段,以确保延迟在秒级内。 OLAP 系统,如 Clickhouse,以流的方式接收处理后的数据,并为用户的临时查询提供服务。 批量存储,如 A...
Apache Paimon | Flink引擎
本文介绍如何在 Flink 中使用 Paimon。 准备 Paimon Jar 文件Paimon 目前支持 Flink 1.17、1.16、1.15 和 1.14。推荐使用最新的 Flink 版本以获得更好的体验。 下载对应版本的 jar 文件: Flink 版本 Jar Flink 1.17 https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-flink-1.17/0.4.0-incubating/paimon-flink-1.17-0.4.0-incubating.jar Flink 1.16 https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-flink-1.16/0.4.0-incubating/paimon-flink-1.16-0.4.0-incubating.jar Flink 1.15 https://repo.maven.apache.org/maven2/org/apache/paimon/pa...
Apache Paimon | 引擎概述
Paimon 不仅原生支持 Flink SQL 的写入和查询,而且还提供其他流行引擎的查询,例如 Apache Spark 和 Apache Hive。 兼容性矩阵 引擎 版本 批读取 批写入 创建表 流写入 流读取 批覆盖 Flink 1.14 - 1.17 ✅ ✅ ✅ ✅ ✅ ✅ Hive 2.1 - 3.1 ✅ ✅ ❌ ❌ ❌ ❌ Spark 3.1 - 3.4 ✅ ✅ ✅ ❌ ❌ ❌ Spark 2.4 ✅ ❌ ❌ ❌ ❌ ❌ Trino 358 - 400 ✅ ❌ ❌ ❌ ❌ ❌ Presto 0.236 - 0.279 ✅ ❌ ❌ ❌ ❌ ❌ 正在进行的引擎: Doris:开发中,支持Paimon目录,Doris 产品路线图 2023。 Seatunnel:开发中,引入 Paimon 连接器。 Starrocks:正在讨论中。 (END)
Apache Paimon | 外部日志系统
除了底层表文件的变更日志外,Paimon 的变更日志也可以存储在外部日志系统中,比如 Kafka,或者从外部日志系统中消费。通过指定 log.system 表属性,用户可以选择使用哪个外部日志系统。 如果选择使用外部日志系统,那么所有写入表文件中的记录也会写入日志系统。因此,流查询产生的变化会从日志系统读取,而不是表文件。 一致性保证默认情况下,日志系统中的变化要等到快照之后才对消费者可见,就像表文件一样。这种行为保证了精确一次的语义。也就是说,每条记录只被消费者看到一次。 但是,用户也可以指定表的属性 'log.consistency' = 'eventual',这样写进日志系统的变更日志就可以立即被消费者消费,而不用等待下一个快照。这种行为减少了变更日志的延迟,但由于可能发生的故障,它只能保证至少一次的语义(即,消费者可能会看到重复的记录)。 如果设置 'log.consistency' = 'eventual',为了获得正确的结果,Flink 中的 Paimon 源将自动添加“normalize”运算符进行重复...
Apache Paimon | 仅追加表(Append Only 表)
如果一个表没有定义主键,那么它默认是一个 append-only 表。 你只能向表中插入完整的记录。不支持删除或更新,也不能定义主键。这种类型的表适用于不需要更新的用例(例如日志数据同步)。 分桶(Bucketing)你也可以为 Append-only 表定义桶的数量,见 Bucket。 建议设置 bucket-key 字段。否则,数据会按照整行进行散列,性能会很差。 压缩(Compaction)默认情况下,接收节点(sink 节点)将自动进行压缩以控制文件数量。以下选项控制压缩策略: Key 默认值 类型 描述 write-only false Boolean 如果设置为 true,压缩和快照过期将被跳过。此选项与专门的压缩作业一起使用。 compaction.min.file-num 5 Integer 对于文件集 [f_0,…,f_N],满足 sum(size(f_i)) >= targetFileSize 的最小文件数,以触发仅追加表的压缩操作。此值可避免压缩几乎完整的文件,这不符合成本效益。 compaction.max.file-num ...

