Introduction to HTML
Overview
HTML is the language of the web, defining the structure and content of web pages. When a browser visits a website, it essentially downloads HTML code from the server and renders it into a webpage.
HTML stands for “HyperText Markup Language,” invented in the early 1990s by Tim Berners-Lee, a physicist at CERN (European Organization for Nuclear Research). Its most distinctive feature is support for hyperlinks, allowing users to jump to other web pages with a simple click, thus forming the foundation of the entire internet.
HTML 4.01, released in 1999, became the widely accepted HTML standard. The current version, HTML 5, was released in 2014 and is in use today.
Web development involves three key technologies: HTML, CSS, and JavaScript. HTML defines the structure and content of web pages, CSS determines their style, and JavaScript enables user interaction. HTML forms the foundation of web development; CSS and JavaScript build upon it. Even without these two, HTML alone can display basic content. This tutorial focuses solely on HTML.
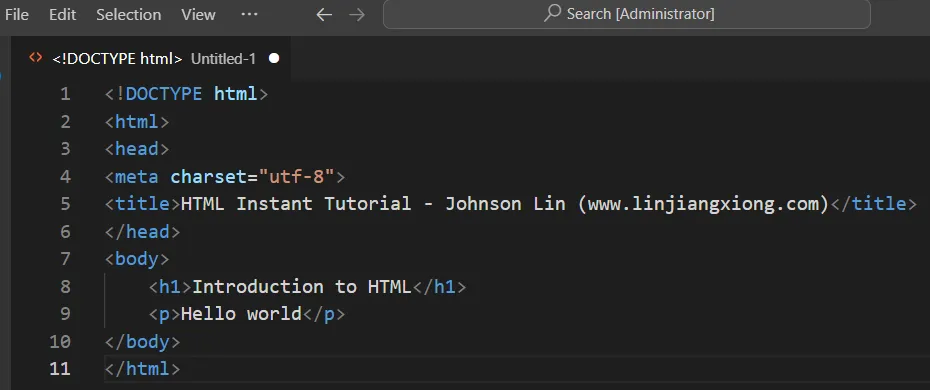
Here’s a simple example of HTML source code:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<html lang="en">
<head>
<meta charset="utf-8">
<title>Page Title</title>
</head>
<body>
<p>Hello World</p>
</body>
</html>
You can save this code as “hello.html”. Opening this local file in a browser will display the text “Hello World”.
To view the HTML source code of any webpage, right-click and select “View page source” in your
Basic Concepts
Tags
HTML code for web pages consists of numerous different tags. Learning HTML essentially means learning how to use these various tags.
Here’s an example of a tag:1
<title>Page Title</title>
In this code, <title> and </title> form a pair of tags.
Tags tell the browser how to handle the enclosed content. The content between tags is what the browser renders and displays on the web page.
Tags are enclosed in angle brackets (like <title>). Most tags come in pairs: an opening tag and a closing tag. The closing tag includes a forward slash before the tag name (like </title>). However, some tags are self-closing and don’t require a separate closing tag, such as the <meta> tag from our earlier example:1
<meta charset="utf-8">
These self-closing tags typically provide instructions to the browser without needing to enclose any content.
Tags can be nested:1
<div><p>hello world</p></div>
Here, the <div> tag contains a <p> tag.
When nesting tags, ensure proper closing order to avoid unexpected rendering results:1
<div><p>hello world</div></p> <!-- Incorrect nesting -->
HTML tag names are case-insensitive, so <title> and <TITLE> are the same tag. However, lowercase is generally preferred.
HTML ignores indentation and line breaks. The following examples will render identically:1
2
3
4
5
6
7
8<title>Page Title</title>
<title>
Page Title
</title>
<title>Page
Title</title>
In fact, an entire HTML document could be written on a single line and still be parsed correctly by browsers. Developers sometimes compress their code to a single line before publishing to reduce file size.
Page styling effects like indentation and line breaks are primarily achieved through CSS.
Elements
When a browser renders a web page, it parses the HTML source into a tag tree, with each tag becoming a node. These nodes are called elements. “Tag” and “element” are essentially synonymous, but used in different contexts: we talk about tags in source code and elements in programming.
Nested tags create a hierarchy of elements:1
<div><p>hello world</p></div>
Here, the div element contains a p element. The outer element is called the “parent element,” and the inner one is the “child element.”
Block vs. Inline Elements
Elements fall into two main categories: block-level and inline.
Block-level elements occupy their own space, starting on a new line and typically taking up 100% of the available width:1
2<p>hello</p>
<p>world</p>
These p elements will display on separate lines.
Inline elements flow within the text and don’t force new lines:1
2<span>hello</span>
<span>world</span>
These span elements will display on the same line.
Attributes
Attributes provide additional information for tags, separated from the tag name and other attributes by spaces:1
<img src="demo.jpg" width="500">
Here, the <img> tag has two attributes: src and width.
Attribute values are specified with an equals sign and are usually enclosed in double quotes (recommended but not required).
Note that attribute names are case-insensitive, so onclick and onClick are the same attribute.
HTML offers numerous attributes to customize tag behavior. For more details, refer to the “Element Attributes” chapter.
Basic HTML Tags
A web page that complies with HTML standards should have the following basic structure:1
2
3
4
5
6
7
8
9
<html lang="en">
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
</body>
</html>
Every web page, no matter how complex, is derived from this basic structure.
As mentioned earlier, indentation and line breaks in HTML code don’t affect browser rendering. The above code could be written on a single line with the same result. We format it this way for better readability.
Let’s explore the main tags that form the skeleton of a web page:
<!doctype>
The first tag in a web page is usually <!doctype>, which declares the document type and tells the browser how to parse the page.
Generally, a simple declaration like this is sufficient:1
This tells the browser to process the page according to HTML5 rules.
Sometimes, this tag is written in all caps to distinguish it from regular HTML tags, as it’s more of a processing instruction than a true tag:1
<html>
The <html> tag is the top-level container for the web page, or the root element of the tag tree structure. All other elements are its children. A web page can have only one <html> tag.
Its lang attribute indicates the default language of the page content:1
<html lang="en">
This example shows that the page content is in English. For more detailed information, see the “Element Attributes” chapter.
<head>
The <head> tag is a container for metadata about the web page. Its content doesn’t appear on the page itself but provides additional information for rendering.1
2
3
4
5
6
<html>
<head>
<title>Page Title</title>
</head>
</html><head> is the first child element of <html>. If a page doesn’t include <head>, the browser will create one automatically. <head> typically contains seven types of child elements, which we’ll discuss in detail later:
<meta>: Sets metadata for the page.<link>: Connects external stylesheets.<title>: Sets the page title.<style>: Contains embedded stylesheets.<script>: Imports scripts.<noscript>: Specifies content to display when the browser doesn’t support scripts.<base>: Sets the base URL for relative URLs within the document.
<meta>
The <meta> tag is used to set or describe metadata for the web page and must be placed inside the <head>. Each <meta> tag represents one piece of metadata, and a page can have multiple <meta> tags. By convention, <meta> tags are placed at the beginning of the <head> content.
Generally, every web page should include at least these two <meta> tags:1
2
3
4
5<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Page Title</title>
</head>
In this example, the first <meta> tag specifies that the page uses UTF-8 encoding, while the second enables automatic scaling on mobile devices.
The <meta> tag has five attributes, which we’ll discuss next.
(1) charset Attribute
The charset attribute of the <meta> tag specifies the character encoding for the web page. This attribute is crucial; if set incorrectly, the browser may not decode the content properly, resulting in garbled text.1
2htmlCopy code
<meta charset="utf-8">
This declares the page as UTF-8 encoded. While developers can use other encoding methods, UTF-8 is almost always the correct choice.
Note that the declared encoding should match the actual encoding of the page. If UTF-8 is declared but the page is actually saved in a different encoding (like GB2312), the browser won’t automatically convert the encoding, potentially resulting in garbled text.
(2) name and content Attributes
The name attribute of the <meta> tag specifies the name of the metadata, while the content attribute specifies its value. Used together, they can define a piece of metadata for the page.1
2
3
4
5<head>
<meta name="description" content="Introduction to HTML">
<meta name="keywords" content="HTML,tutorial">
<meta name="author" content="John Doe">
</head>
This code includes three pieces of meta description (a summary of the page content), keywords (key terms related to the page content), and author (the page’s creator).
There are many types of metadata, most of which relate to internal browser mechanisms or specific use cases. Here are a few more examples:1
2
3
4
5<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="application-name" content="Application Name">
<meta name="generator" content="program">
<meta name="subject" content="your document's subject">
<meta name="referrer" content="no-referrer">
(3) http-equiv and content Attributes
The http-equiv attribute of the <meta> tag is used to supplement HTTP response header fields. If the server’s HTTP response is missing a certain field, it can be added using this attribute. The content attribute provides the corresponding field content. These attributes are related to the HTTP protocol and are considered advanced usage, so we won’t go into detail here.1
<meta http-equiv="Content-Security-Policy" content="default-src 'self'">
This sets the Content-Security-Policy field of the HTTP response.
Here are some more examples:1
2
3<meta http-equiv="Content-Type" content="Type=text/html; charset=utf-8">
<meta http-equiv="refresh" content="30">
<meta http-equiv="refresh" content="30;URL='http://website.com'">
<title>
The <title> tag specifies the title of the web page, which appears in the browser’s title bar or tab.1
2
3<head>
<title>Page Title</title>
</head>
Search engines use this tag to display the title of each page in search results. It has a significant impact on the page’s search engine ranking and should be carefully crafted to reflect the page’s main topic.
The <title> tag can only contain plain text, not other tags.
<body>
The <body> tag is a container for the main content of the web page. All visible page content goes inside this tag. It’s the second child element of <html>, immediately following <head>.1
2
3
4
5
6
7
8<html>
<head>
<title>Page Title</title>
</head>
<body>
<p>hello world</p>
</body>
</html>
Whitespace and Line Breaks
HTML has its own rules for handling whitespace. Leading and trailing spaces within tag content are ignored:1
<p> hello world </p>
The spaces before “hello” and after “world” are ignored by the browser.
Multiple consecutive spaces (including tabs) within tag content are collapsed into a single space:1
<p>hello world</p>
This will render with only one space between “hello” and “world”.
Browsers also replace newline (\n) and carriage return (\r) characters in text with spaces:1
2
3
4
5
6<p>hello
world
</p>
This will render with a single space between “hello” and “world”.
This means that line breaks in HTML source code don’t create line breaks in the rendered output.
Comments
HTML code can include comments, which browsers automatically ignore. Comments start with <!-- and end with -->, like this:1
<!-- This is a comment -->
Comments can span multiple lines, and any HTML within them is ineffective:1
2
3<!--
<p>hello world</p>
-->
This entire block is a comment, and the code inside won’t be parsed or rendered by the browser.
Comments are helpful for explaining code, especially before complex code blocks.
Link to original article:
https://wangdoc.com/html/intro